Extract Tables From PDF
Description
Extracts tables from a PDF file.
Design Time Configuration
At design time, you can configure the following properties:
- PDF File Path—The PDF file path from which you want to extract tables.
- Page(s) to read – Use the options below to read the tables within one or more pages.
| Option | Description |
|---|---|
| All | Choose this option to read the tables on all the page(s). |
| Single | Choose this option to read the tables on one page. |
| Range | Choose this option to read the tables on the specified page(s) range. |
- From page - This option is visible when you choose Range in Page(s) to read. Specify the initial page to initiate the table's reading.
- To page—This option is visible when you choose Range in Page(s) to read. Specify the concluding page number within the range for the table's reading.
- Page number - This option is visible when you choose Single in Page(s) to read. Specify the specific page number for reading the tables.
- Table Style - Specify if the table you are extracting is in Spreadsheet format or Basic table with irregular structure.
| Option | Description |
|---|---|
| Spreadsheet | Choose this option if the table style is in Spreadsheet format. |
| Basic | Choose this option if the table style has an irregular structure. |
- Result – Returns Tables of type Dataset extracted from the PDF file.
If the table spans pages, the activity will merge and provide the data in one data table only if the header row is repeated at the start of every page. Otherwise, the activity will return a separate data table per page.
If two continuous tables in the document have duplicate header rows, the activity will merge these two tables into one data table.
-
Table Data Preview dialog — Clicking on the Preview button opens a dialog to test different settings and preview the data. The process fetches the same data when it executes.
Properties
Input
- Include Column Names—Specifies whether the first row in the tables should be considered a header row containing the column names.
If Include Column Names is false, then the Column name will have default Column name values like Column0, Column1, and so on."
- Password—Specify the file's password if password protected.
Misc
- DisplayName – Add a display name to your activity.
- Private – By default, activity will log the values of your properties inside your workflow. If private is selected, then it stops logging.
Optional
- Continue On Error – It Specifies whether the automation should continue even when the activity throws an error. If True, the activity continues without throwing any exceptions. If False, the activity throws an exception. The default value is False.
Catches no error if this activity is present inside the Try-Catch block and the value of this property is True.
Example
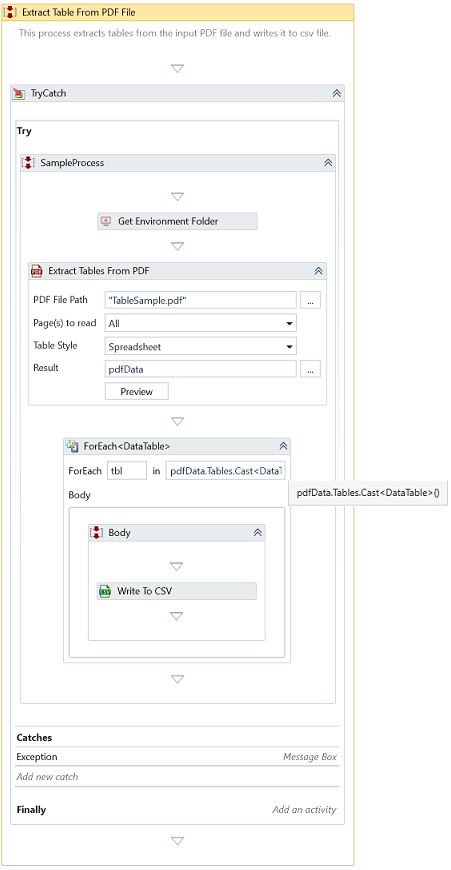
In this example, we will show how to extract table data from a PDF document and import it into a CSV file. The PDF file shipped, and the example process contains multiple tables extracted into CSV files.
Download Example