Architecture
Overview
The IB-X Knowledge Ingestion Service is an enterprise-grade semantic ingestion and retrieval platform designed to provide Agent-specific knowledge retrieval for AI powered Agents.
The platform transforms structured, semi-structured, and unstructured content into semantically searchable knowledge by combining:
- Content extraction
- Semantic chunking
- Embedding generation
- Vector storage
- Graph relationships
- AI-powered retrieval
The architecture is designed around isolated Agent knowledge boundaries where each Agent maintains its own semantic knowledge space.
High-Level Architecture
The Knowledge Ingestion pipeline follows the processing architecture below:
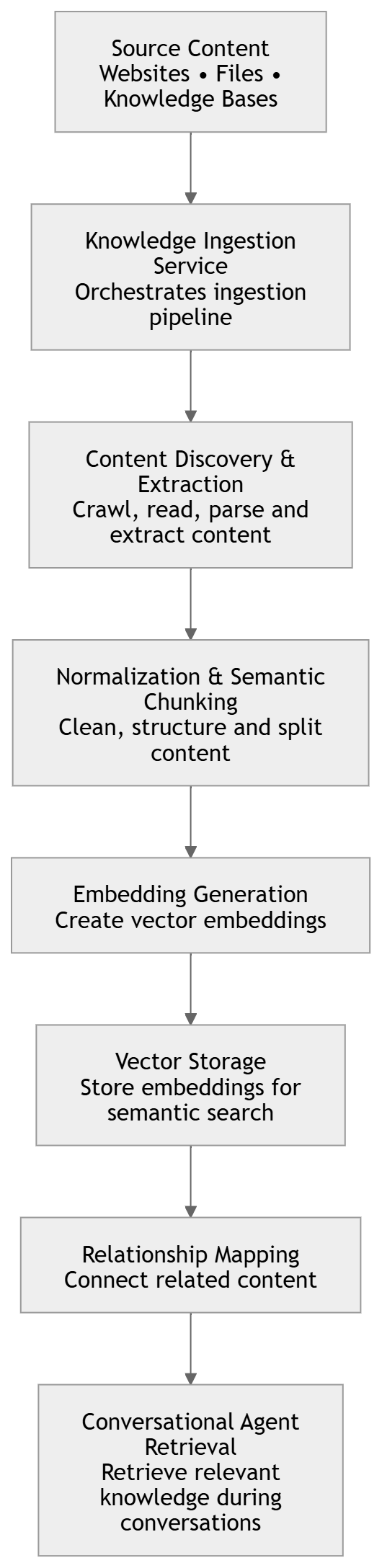
Ingestion Pipeline
The ingestion engine processes content through multiple stages.
1. Source Discovery
The ingestion engine discovers and loads content from supported sources.
Supported source types include:
- Website URLs
- Uploaded files
- Video URLs
For website ingestion, the engine can:
- Crawl website structures
- Discover linked pages
- Parse sitemap structures
- Build hierarchical content maps
2. Content Extraction
The ingestion engine extracts semantic content from discovered sources.
Supported extraction types include:
| Type | Description |
|---|---|
| Text | Written content extraction |
| Image | Image analysis and OCR |
| Audio | Audio transcript extraction |
| Video | Video transcript and metadata extraction |
| Document | Structured document parsing |
Image-based extraction may use configurable image extraction prompts.
3. Content Normalization
Extracted content is normalized into a standardized semantic representation.
Normalization may include:
- Text cleanup
- Structural parsing
- Metadata enrichment
- Content classification
- Semantic grouping
4. Semantic Chunking
Normalized content is divided into semantic chunks optimized for retrieval operations.
Chunking improves:
- Retrieval precision
- Context relevance
- Embedding efficiency
- Conversational grounding
5. Embedding Generation
The ingestion engine generates semantic embeddings for processed content chunks.
Embeddings are numerical vector representations used for semantic similarity search.
The embedding pipeline is orchestrated through the configured AI service infrastructure.
6. Vector Storage
Generated embeddings are persisted in the configured Vector Store.
IB-X currently supports:
- Qdrant
The Vector Store enables:
- Semantic similarity search
- Context retrieval
- Embedding indexing
- Vector-based ranking
7. Relationship Mapping
Optional relationship mapping stores semantic relationships in the configured Graph Database.
IB-X currently supports:
- Neo4j
Relationship mapping enables:
- Knowledge traversals
- Entity relationships
- Semantic linking
- Graph-based retrieval scenarios
Retrieval Flow
The Knowledge Ingestion Service enables semantic retrieval for AI-powered activities such as AI Agent, Conversational Agent, and Knowledge Base.
The retrieval flow typically includes:
- User submits a query, prompt, or message
- Semantic search is performed against the Agent's knowledge store
- Relevant embeddings are identified
- Related semantic chunks are retrieved
- Context is supplied to the consuming activity
- The activity generates a grounded response or result
This architecture enables Retrieval-Augmented Generation (RAG) experiences within IB-X.
Agent Knowledge Isolation
Knowledge ingestion in IB-X is Agent-specific.
Each Agent maintains:
- Independent ingestion sources
- Isolated semantic embeddings
- Agent-specific ingestion runs
- Dedicated retrieval context
This architecture prevents unrelated Agents from accessing or retrieving knowledge belonging to another Agent.
The isolation model improves:
- Security
- Contextual relevance
- Knowledge ownership
- Retrieval quality
- Domain specialization
Core Components
Knowledge Ingestion Service
The Knowledge Ingestion Service is responsible for:
- Source discovery
- Content extraction
- Semantic chunking
- Embedding generation
- Metadata persistence
- Retrieval preparation
- Ingestion orchestration
Relational Database
The Relational Database stores operational ingestion metadata.
Stored metadata includes:
- Ingestion definitions
- Runtime metadata
- URL tracking
- Processing state
- Ingestion runs
- Operational records
IB-X currently supports:
- PostgreSQL
Vector Store
The Vector Store stores semantic embeddings and vector indexes.
Responsibilities include:
- Embedding persistence
- Semantic search
- Similarity ranking
- Retrieval optimization
IB-X currently supports:
- Qdrant
Graph Database
The Graph Database stores semantic relationships and traversal structures.
Responsibilities include:
- Relationship modeling
- Semantic linking
- Graph traversals
- Connected retrieval scenarios
IB-X currently supports:
- Neo4j
External Services
External Services provide orchestration and AI infrastructure integration.
Responsibilities include:
- Embedding generation
- AI inference
- Pipeline orchestration
- Operational coordination
Image Extraction Engine
The Image Extraction Engine processes image-based content discovered during ingestion.
Capabilities include:
- OCR extraction
- Semantic interpretation
- Context generation
- Image-based knowledge extraction
The extraction behavior can be customized using configurable extraction prompts.
Storage Architecture
The platform separates storage responsibilities across specialized infrastructure components.
| Component | Responsibility |
|---|---|
| Relational Database | Operational metadata |
| Vector Store | Semantic embeddings |
| Graph Database | Relationships and traversals |
This separation improves scalability, retrieval efficiency, and operational maintainability.
Licensing and Usage Model
Knowledge ingestion usage is controlled through subscription entitlements.
The platform tracks:
- Embeddings created
- Bytes ingested
- Characters ingested
The ingestion quota is governed through:
DATA_INGESTION_LIMIT
This quota applies at the environment level.
Administration Scope
Knowledge Ingestion Service infrastructure is configured globally from the root tenant.
Configuration includes:
- Relational Database
- Vector Store
- Graph Database
- External Services
- Image Extraction
These configurations are shared across the environment while the ingested knowledge itself remains Agent-specific.
Notes
- Knowledge ingestion in IB-X is Agent-specific and isolated to the owning Agent.
- Infrastructure configuration for the Knowledge Ingestion Service is performed globally from the root tenant.
- Ingestion usage limits are enforced using the
DATA_INGESTION_LIMITsubscription entitlement. - The Vector Store, Graph Database, and Relational Database are independently configurable infrastructure components.
- Image extraction behavior can be customized using configurable extraction prompts.
Related
See Also
- Conversational Agents
- Agent Designer
- AI Command Center
- Agent Health Model
- Integration Gateway