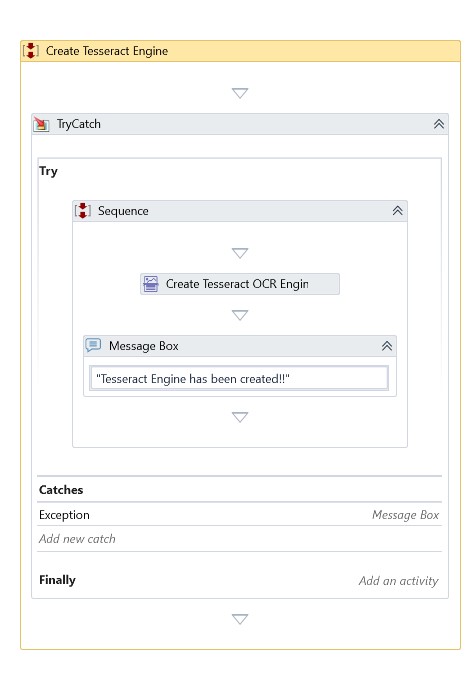
Create Tesseract OCR Engine
Description
This Activity extracts the specified string and related information from a UI element, image, or PDF using the Tesseract OCR Engine. OCR is Optical Character Recognition, a technology programmed to recognize text inside images, like scanned documents and photos.
Properties
Input
- Data Path – Terresact engine path. Default path is 'C:\Users\Public\Documents\IntelliBuddies\tessdata'. You can download trained data from here.
- Image Height Multiplier – Allows image height rescaling by the mentioned percentage.
- Image Width Multiplier – – It allows rescaling an image width by the mentioned percentage.
- Language – It specifies the language used by the OCR engine to extract the text. It can recognize more than 100 languages with Unicode support. An OCR engine can save time by digitizing documents rather than manually typing the content.
Misc
- DisplayName – Add a display name to your Activity.
- Private – By default, Activity will log the values of your properties inside your workflow. If private is selected, then it stops logging.
Optional
- Continue On Error – It Specifies whether the automation should continue even when the Activity throws an error. If True, the Activity continues without throwing any exceptions. If False, the Activity throws an exception. The default value is False.
note
Catches no error if this Activity is present inside the Try-Catch block and the value of this property is True.
Output
- OCR Engine – OCR engine instance returned by the activity Create Tesseract OCR Engine. The Tesseract OCR engine creates language-specified training data to recognize words. It biases the words and sentences that often appear together in a specified language as a human brain does. It produces accurate results with the training data.
Example
Download Example