Extract PDF Data With OCR
Description
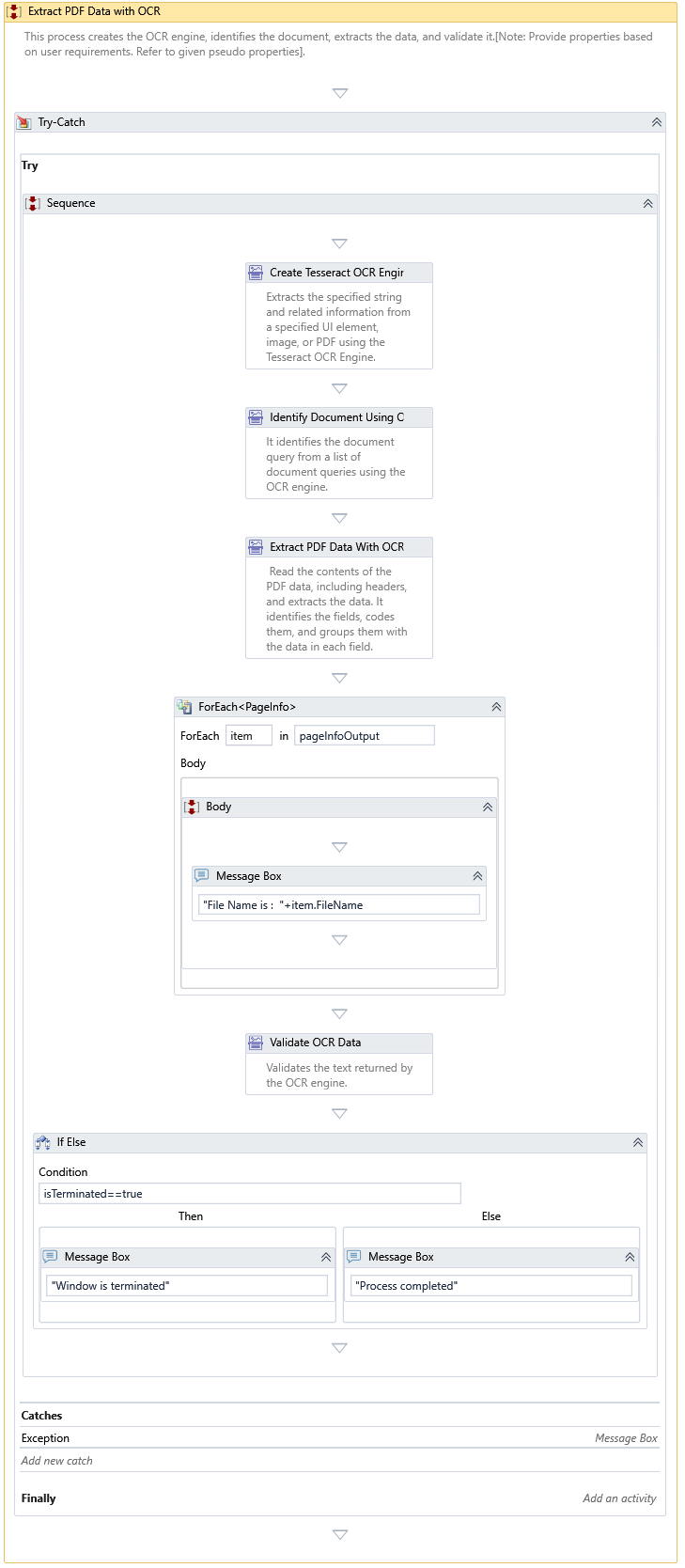
This Activity reads the contents of the PDF data, including headers, and extracts the data. It identifies the fields, codes them, and groups them with the data in each area.
Properties
Input
- Criteria – OCR queries to extract the data from PDF pages.
- From Page Number – Set the page extraction mode into "Range" and specify the page numbers to start the extraction.
- Image Resize Percentage – Enter the percentage value to rescale an image.
- OCR Engine – An instance of an OCR engine returned by one of the following activities.
- Page Extraction Mode – Set the page extraction mode to "All," "Single," or "Range" to continue the extraction.
- Password – The password of the PDF file, if necessary.
- PDF File Path – The name of the PDF file from where you want to extract the data.
- Retain Temp Images – It specifies keeping the exported images in the staging folder or deleting them after the text extraction.
- Single Page Number – Set the page extraction mode to "Single" and specify the page number to extract text.
- Staging Folder – It specifies the path of the exported image folder.
- To Page Number – Set the page extraction mode to "Range" and specify which page to extract the text from.
Misc
- DisplayName – Add a display name to your Activity.
- Private – By default, Activity will log the values of your properties inside your workflow. If private is selected, then it stops logging.
Optional
- Continue On Error – It Specifies whether the automation should continue even when the Activity throws an error. If True, the Activity continues without throwing any exceptions. If False, the Activity throws an exception. The default value is False.
note
Catches no error if this Activity is present inside the Try-Catch block and the value of this property is True.
Output
- Result – The list of pageinfo and its corresponding metadata extracted and returned by this Activity.
Example
Download Example