Overview
Organizational processes are expected to involve understanding several types of documents, such as Invoices, Purchase Orders, Bills, Forms, and many others. As part of automating these processes, it is required that the processing of these documents is also automated. IntelliBuddies provides various OCR activities to support document processing automation. IntelliBuddies can work with multiple OCR Engines. Here is the list of activities supported by IntelliBuddies under this category.
| Activity | Description |
|---|---|
| Create Google Cloud OCR Engine | Creates a handle for Google Cloud OCR Engine so that it will allow you to work with Google Cloud OCR Engine to extract text from Images |
| Create MODI OCR Engine | Creates a handle for MODI (Microsoft Office Document Imaging) OCR Engine so that it will allow you to work with this OCR Engine to extract text from Images |
| Create Tesseract OCR Engine | Creates a handle for Tesseract OCR Engine so that it will allow you to work with this OCR Engine to extract text from Images |
| Extract PDF Text With OCR | Extracts the text from the specified PDF file using the specified OCR Engine handle. You can specify the page range for text extraction. By default, it will extract the text from the entire document |
| Extract PDF Data With OCR | Extracts the data from the specified PDF document based on the specified document processing model |
| Extract Text with OCR | Extracts the text from the specified image using the specified OCR Engine handle and returns back the extracted text |
| Find OCR Closest Text Position | This is similar to Find OCR Text Position except that it utilizes text fuzzy logic to find the closest match by controlling the match tolerance of the search string inside the image |
| Find OCR Text Position | Searches for the specified text in the specified image using the specified OCR Engine handle and returns true, if the search text was found inside the image along with its position, otherwise false |
| Identify Document Using OCR | Identifies the type of the specified document based on the specified document processing model |
| Read Barcode | Detects and decodes the BarCode(s) present in the specified image |
| Read QR Code | Detects and decodes the QR Code(s) present in the specified image |
| Validate OCR Data | Pops up Validator UI to show the data extracted by Extract PDF Data With OCR. You can validate the extracted data and correct it before proceeding to the next step in the process |
| Generate QR Code | Generates a QR code image from the specified content and saves it to the specified folder path. |
OCR Engine
IntelliBuddies allows you to work with different OCR Engines. The capabilities of text extraction from images depend upon each respective Engine's capabilities. As of now, IntelliBuddies supports the following OCR Engines:
- Tesseract OCR Engine
- Google Cloud OCR Engine
- MODI (Microsoft Office Document Imaging) OCR Engine
To support multiple OCR engines in all other activities under this category, you need to create the appropriate OCR engine, obtain a handle for that Engine, and then pass it on to the other activities. IntelliBuddies exposes the handle to these different OCR Engines through the IOCREngine type. IOCREngine will specify the handle for the OCR Engine that was created.
OCR Parameters
You can control the extraction capabilities of the OCR Engine using OCR Parameters. All the OCR activities that perform text extraction can be configured with appropriate OCR Parameters to tune your OCR Engine. You can set these parameters through the OCR Parameters dialog, which can be invoked by clicking on the [...] button available as part of the Properties panel.
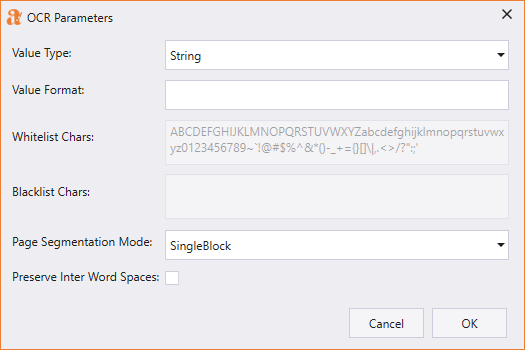
The table below details each of the above parameters:
| Parameter | Description |
|---|---|
| Value Type | The type of value is extracted. IntelliBuddies supports certain pre-defined value types listed in the drop-down. |
| Value Format | Regular expression pattern to validate the extracted value format. An error will be reported if the value does not match the expected pattern. |
| Whitelist Chars | The characters could be part of the extracted value. This will be set based on the Value Type selected. You can control these character sets for the Custom value type. |
| Blacklist Chars | The characters should not appear as part of the extracted value. This will be set based on the Value Type selected. You can control these character sets for the Custom value type. |
| Page Segmentation Mode (psm) | Page segmentation mode defines how your text should be treated by OCR Engine. For example, if your image contains a single character or a text block, you want to specify the corresponding psm to improve accuracy. By default, the PSM would be set to Sparse Text. |
| Preserve Inter Word Spaces | When this flag is checked, the text will be extracted from the image by preserving the spaces as per the original image. By default, this is unchecked, and the extracted text spaces would be trimmed. |
Clipping Region
The activities such as Extract Text With OCR will, by default, extract the text from the entire image. However, you can specify the region where you want to extract the text from the image. The region could be selected optionally as part of the corresponding activity's Clipping Region property. This Clipping Region is of type BoundingRect, which denotes the rectangular region regarding pixel coordinates inside the image.

TextResult
All OCR extraction activities return the result as TextResult. TextResult encapsulates the extracted text along with other information related to the extraction. You can get the text extracted from the Text property of this TextResult object.
Document Processing
IntelliBuddies supports document processing automation through the IntelliTrainer component of IntelliBuddies. You can use IntelliTrainer to create document models, which our Buddies will later use to identify and extract data from the documents.
DocumentQueries
You can use our IntelliTrainer to train with multiple document templates. The IntelliTrainer exports the trained document model as DocumentQueries. The DocumentQueries is a list of DocumentQuery, where each DocumentQuery holds the training information for the corresponding document template that was part of the training.
When DocumentQueries is used as part of Identify Document With OCR activity, the activity will process the specified input document with all the trained document templates embedded as part of specified DocumentQueries. If it finds the specified document matching any of the trained document templates, it will return the corresponding DocumentQuery model.
PageQueries
The document might have one or more pages. Hence, it becomes essential to identify each of the pages of your interest and extract corresponding data from that page. As part of document training using our IntelliTrainer, you can train documents at the page level to specify how to identify individual pages and what kind of data needs to be extracted from the corresponding pages. DocumentQuery embeds this page-level training into PageQueries property.
You must pass this PageQueries as input criteria to Extract PDF Data With OCR activity. The activity will then process individual pages of the specified input document against the PageQueries to identify the pages that need to be processed.
PageInfo
The output of Extract PDF Data With OCR will return backlist of PageInfo. Each PageInfo contains extracted data and corresponding metadata information for a corresponding page. The result would be the list of PageInfo based on the number of pages it picked to process based on the PagePageQueriesQueries model.