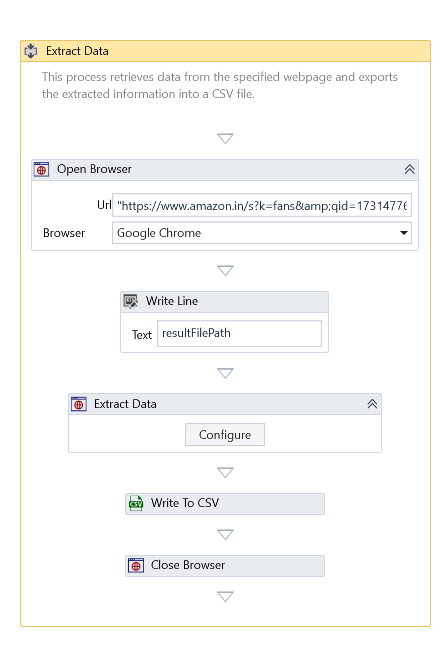
Extract Data
Description
The Extract Data activity enables data extraction from multiple web pages, applies filtering, and structures the data into a specified format for further processing.
Design-Time Configuration
The Extract Data Selector Configuration dialog generally allows the following properties to be configured.
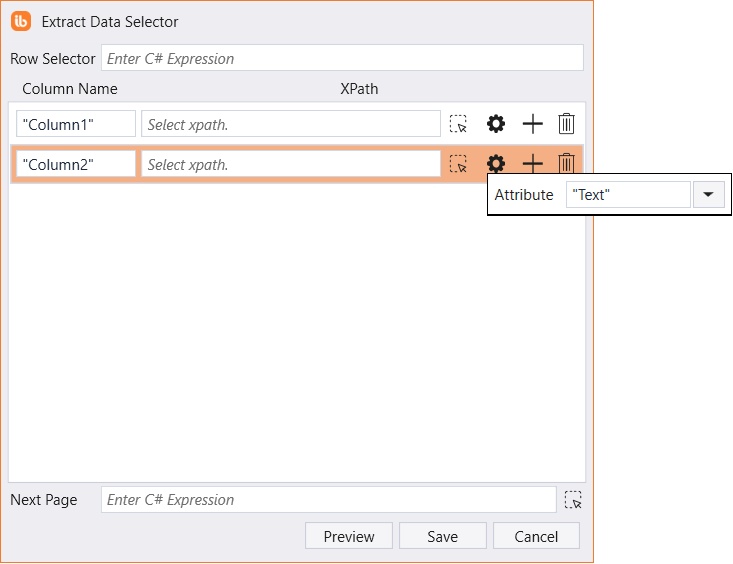
| Property | Description |
|---|---|
| Row Selector | XPath expression for row selection. |
| columnSelector | Defines column properties: Column Name – The identifiable column name.XPath – The column selection XPath.Attribute – The attribute value to extract. |
| Next Page | XPath expression for navigating to the next page. |
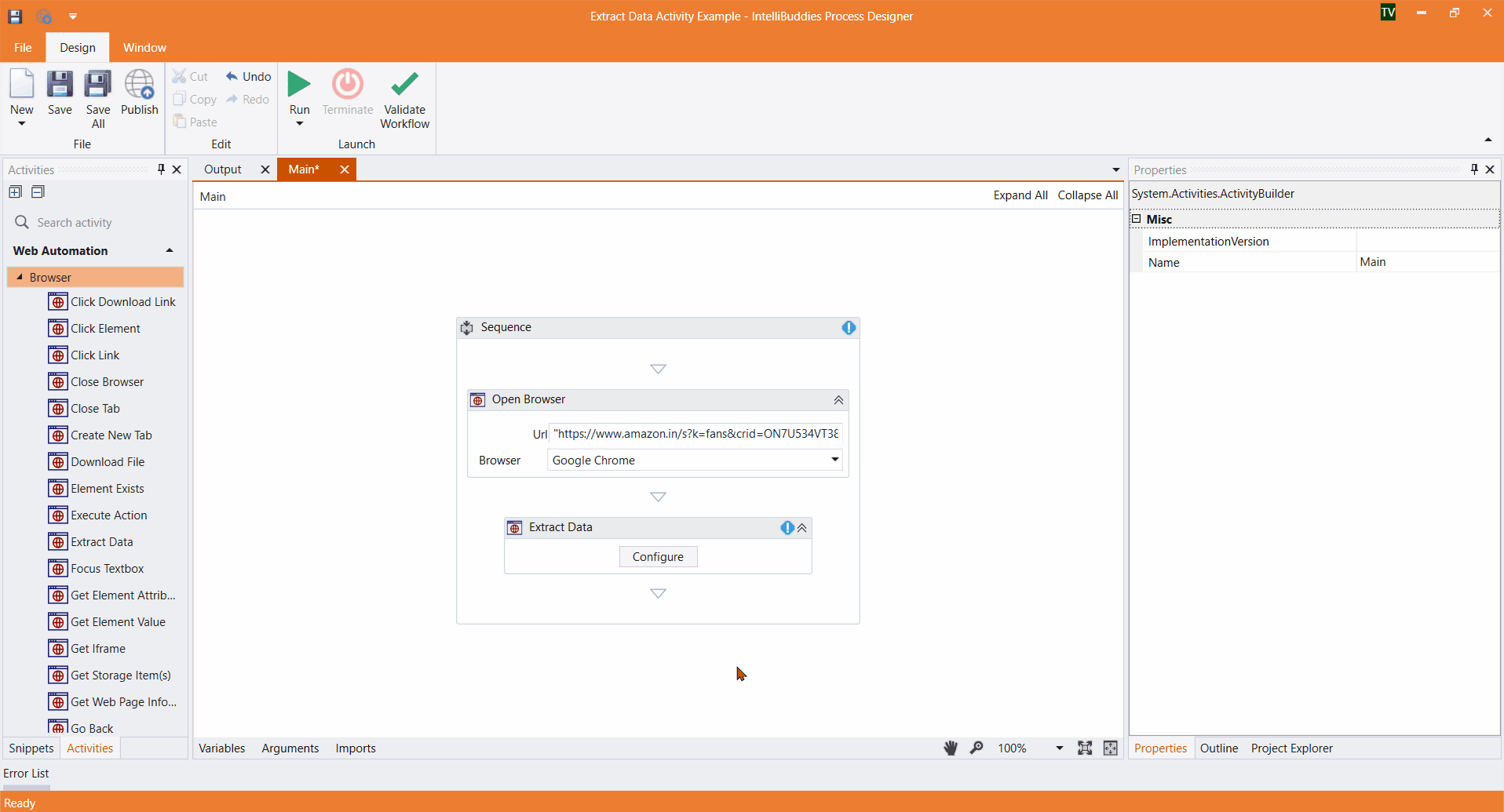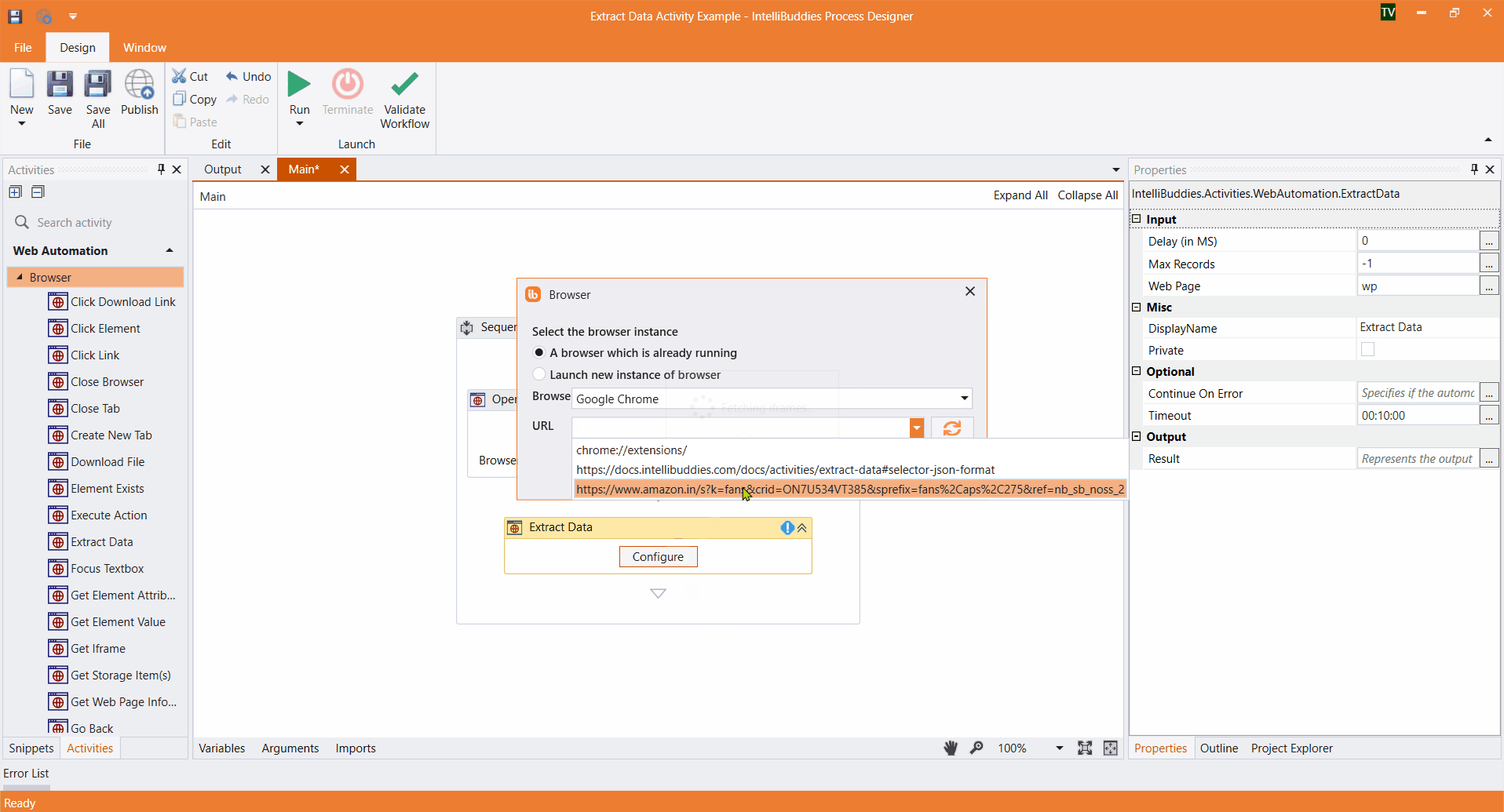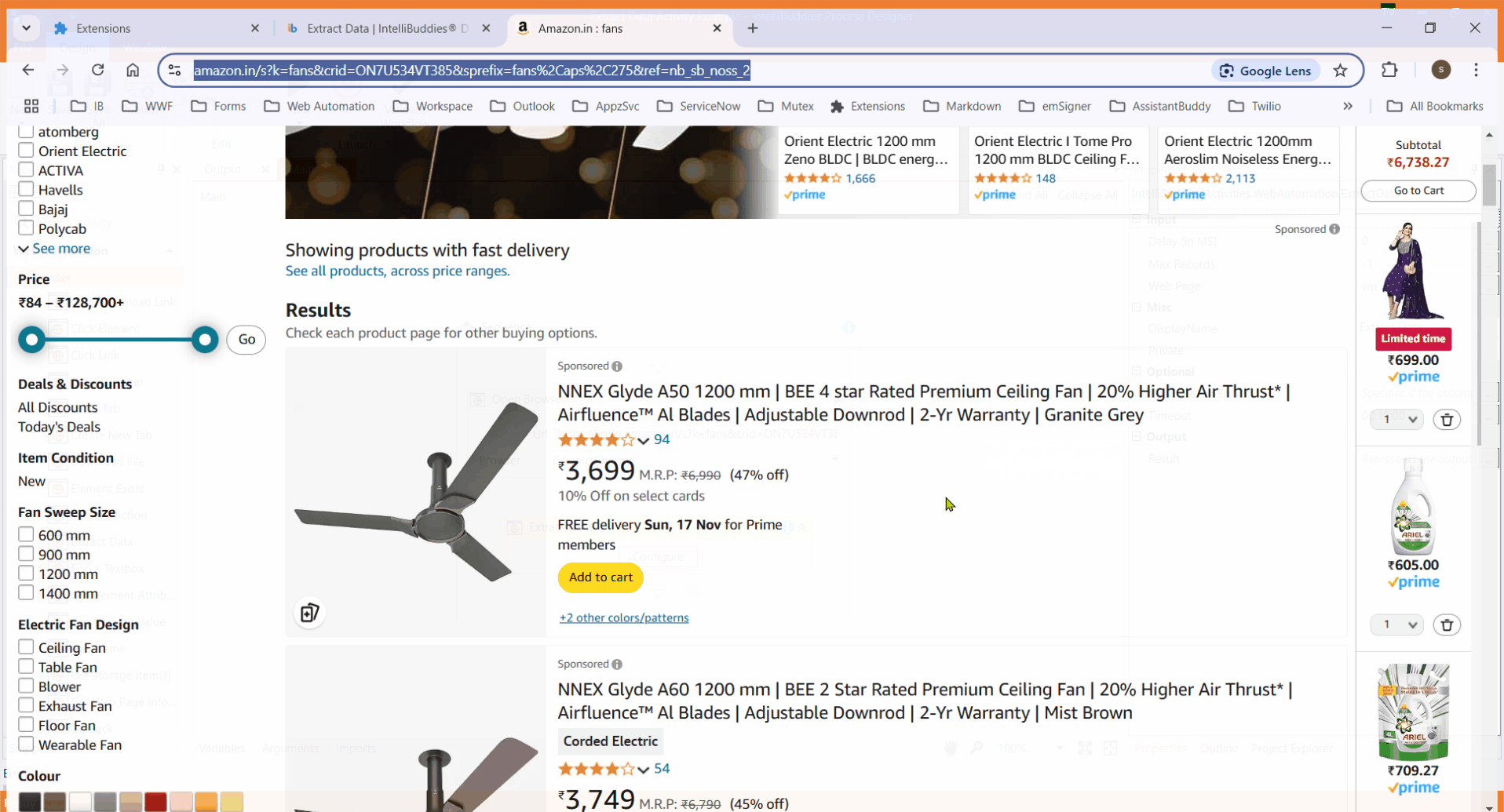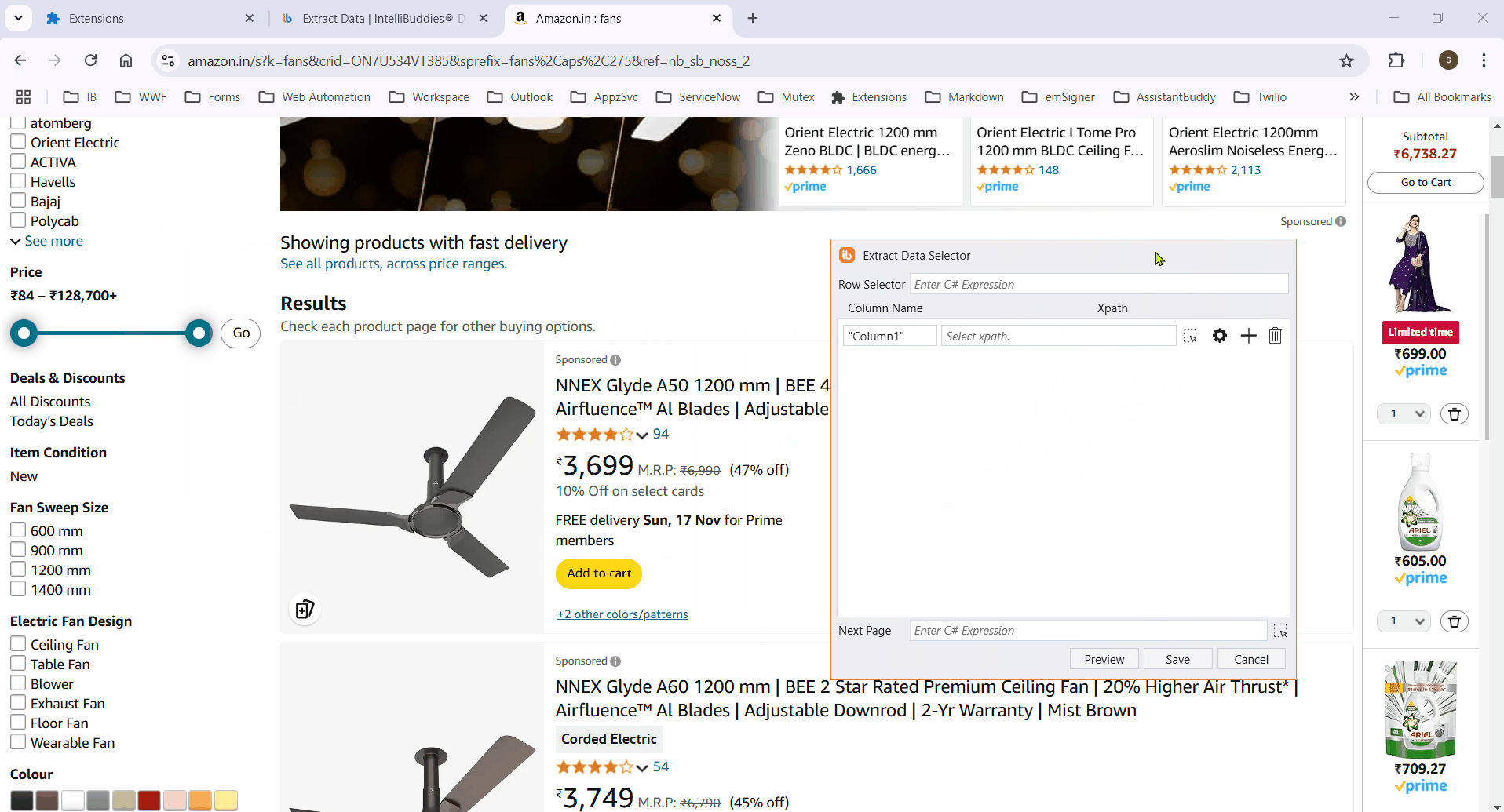
It is better to understand the configuration of this activity with an example use case.
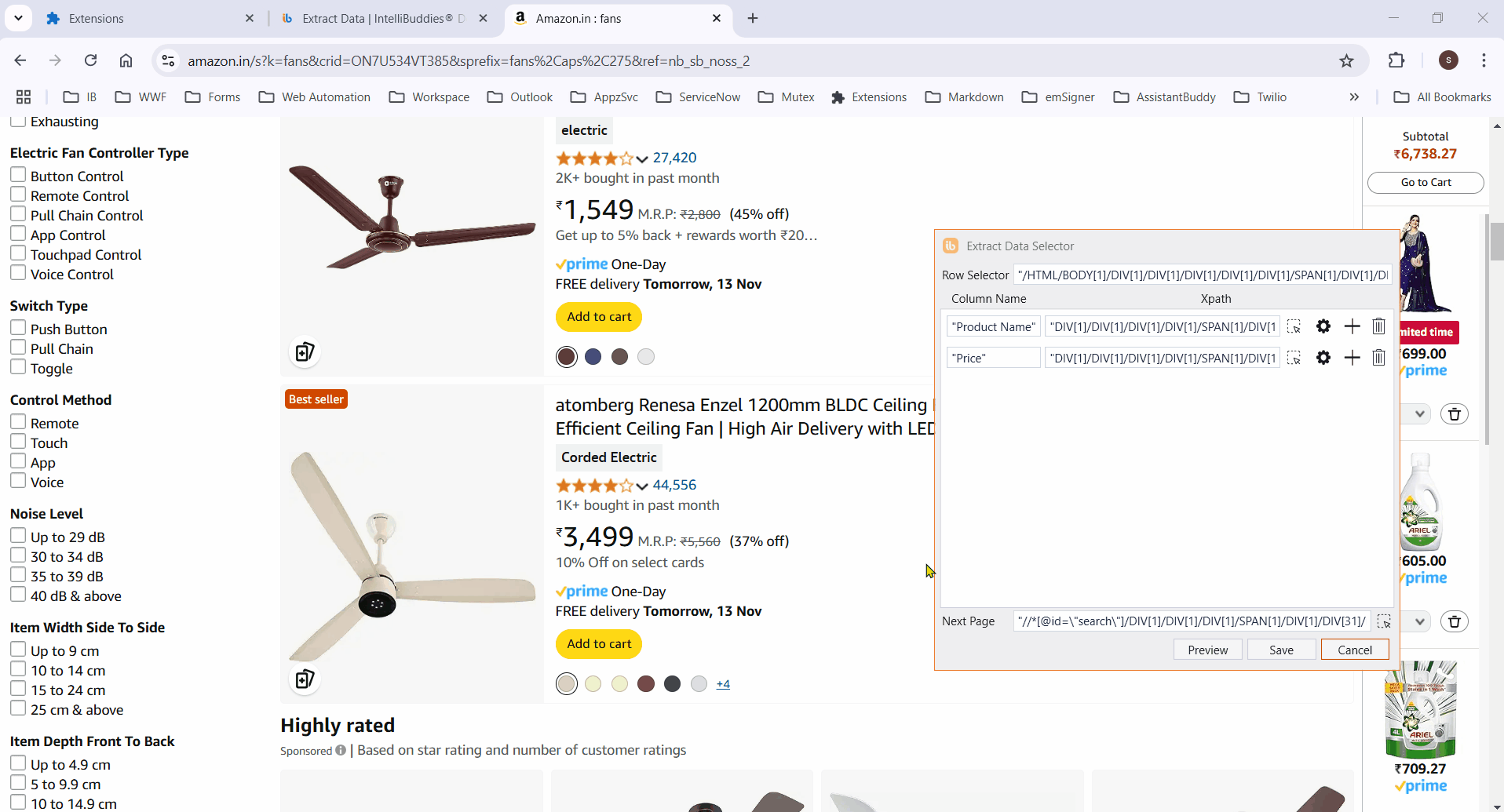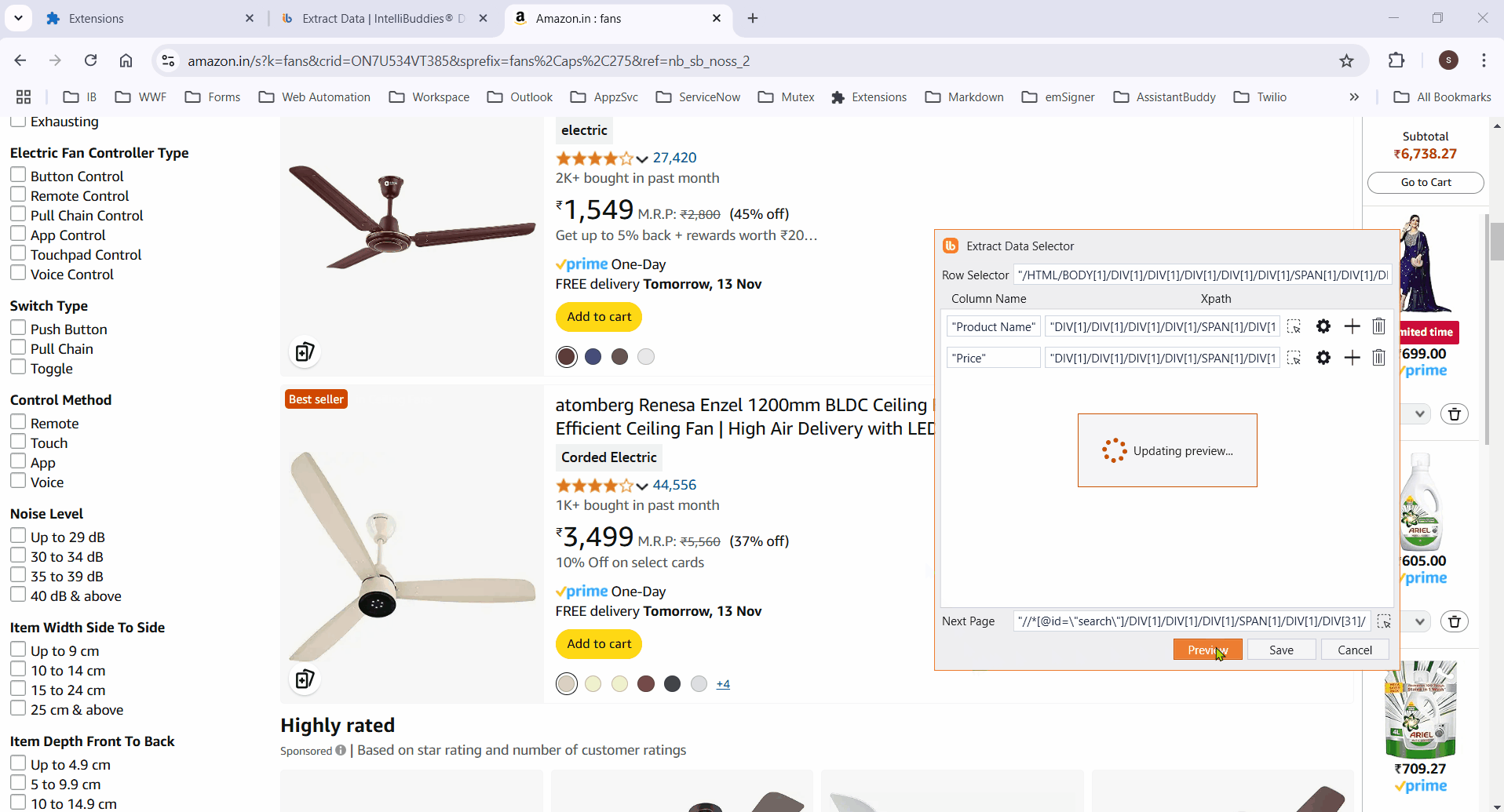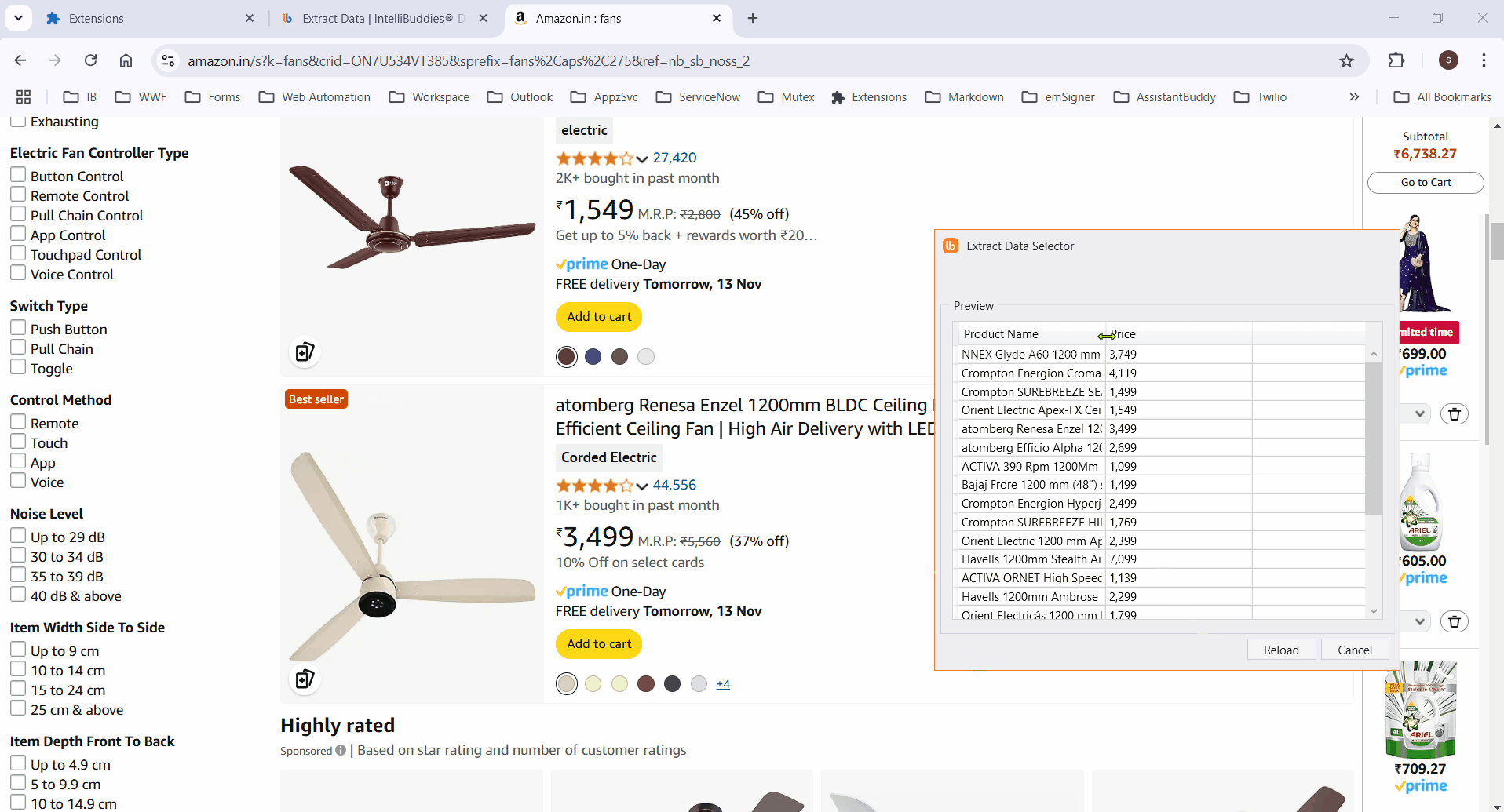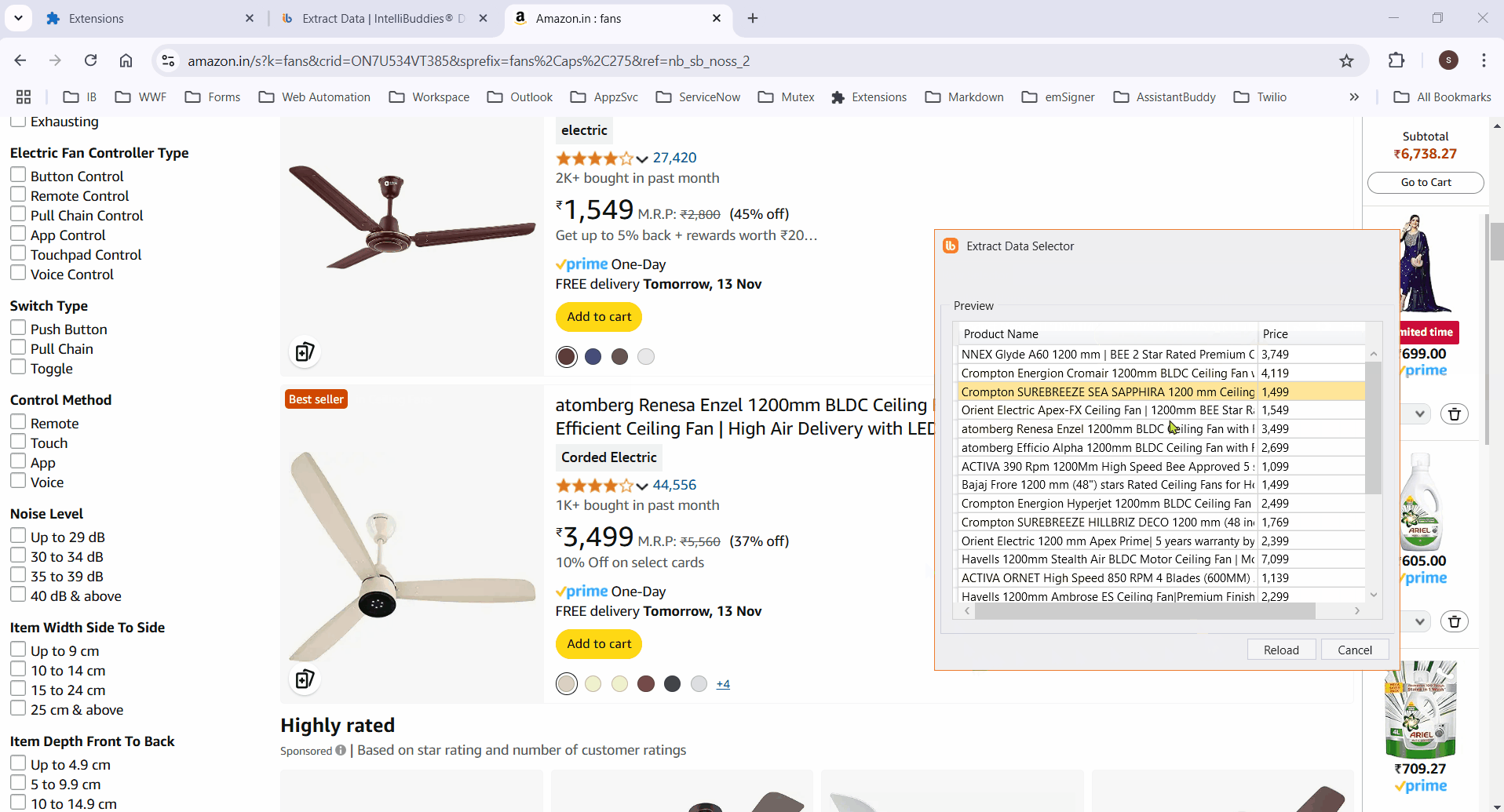
For this example, we will extract the Product Name and Price from this Amazon URL.
- Click Configure and select Browser and URL. This opens the Extract Data Selector dialog.
- Enter the column name, then click the
 button to activate element selection.
button to activate element selection.
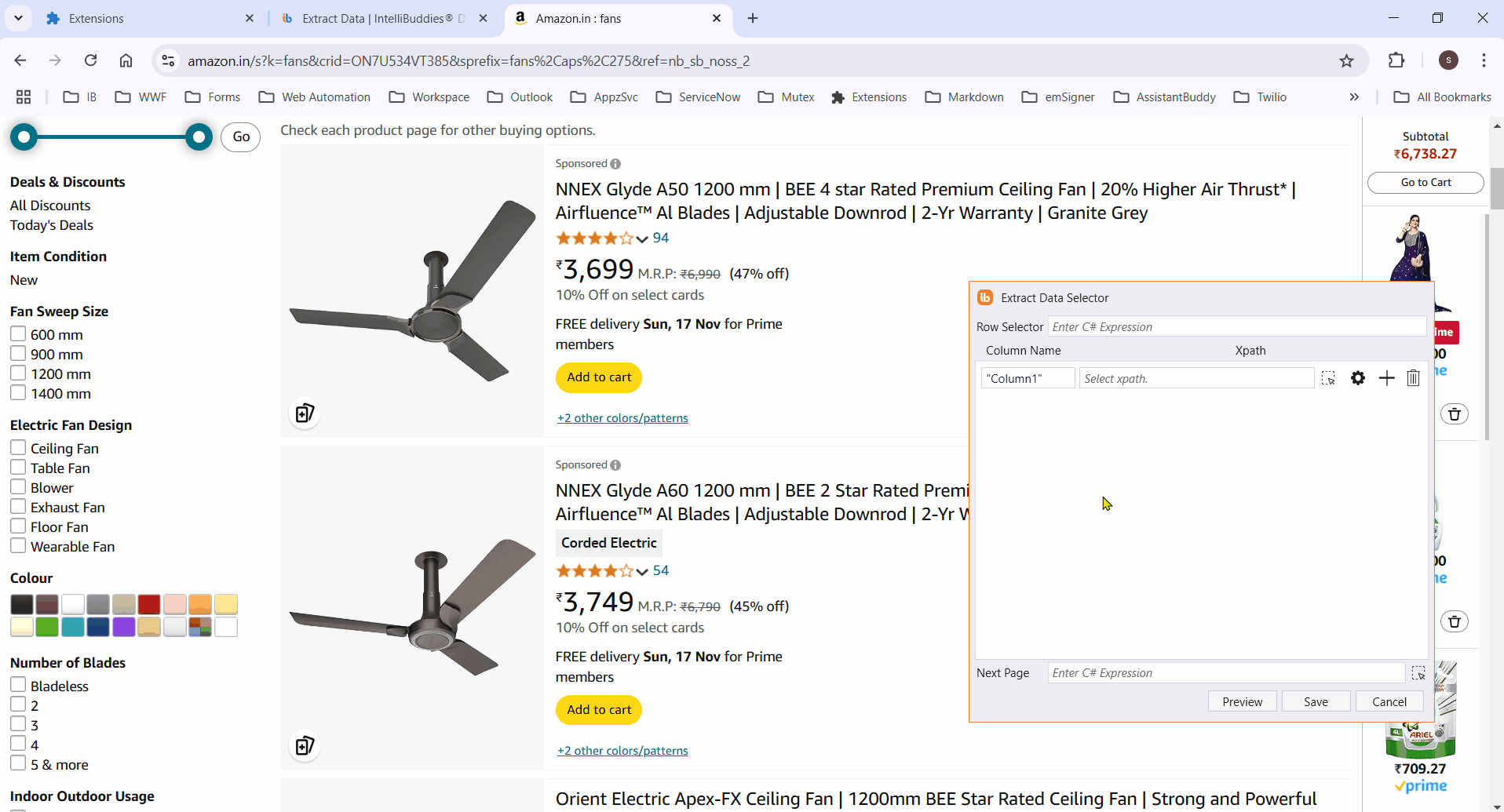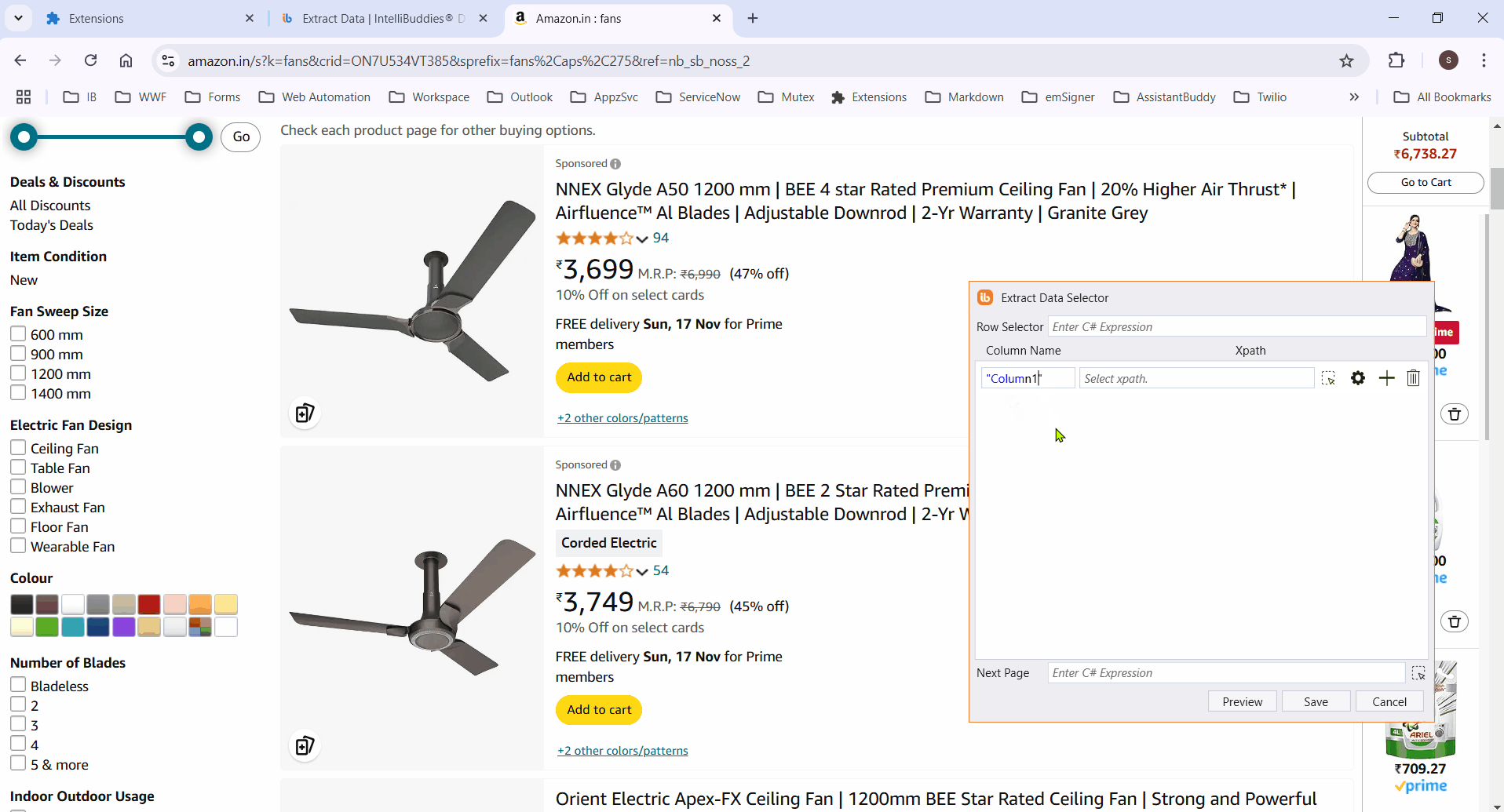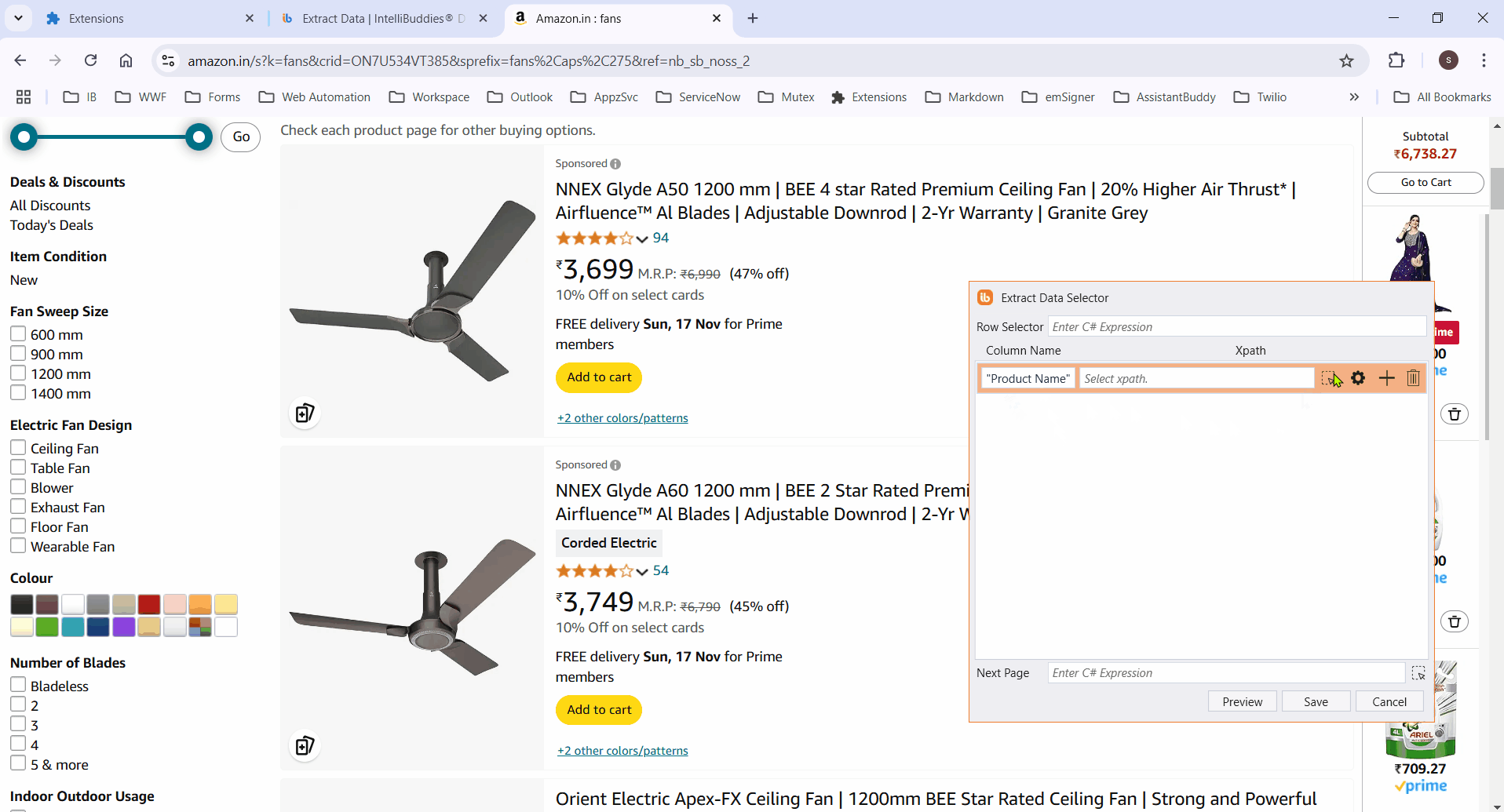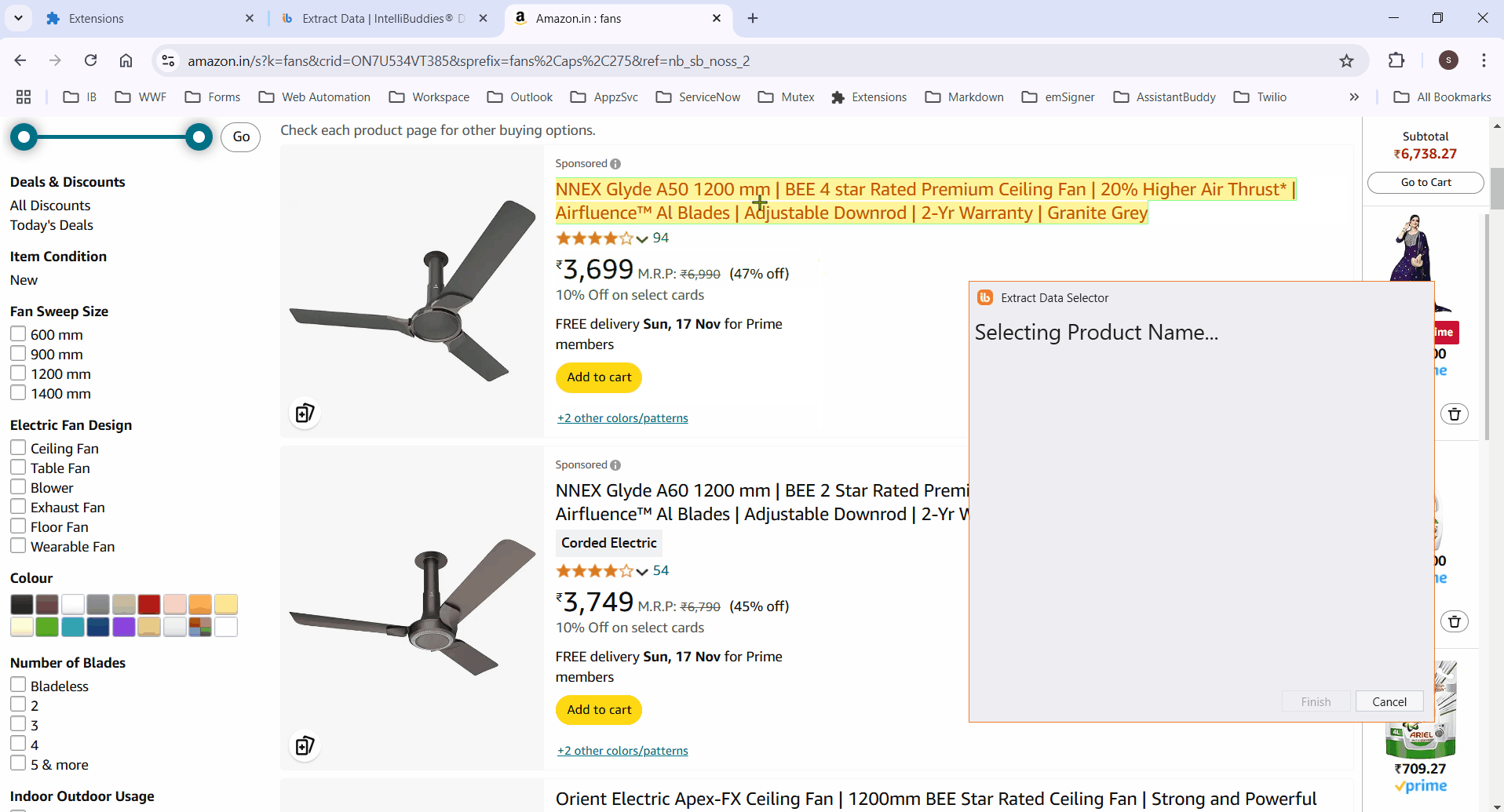
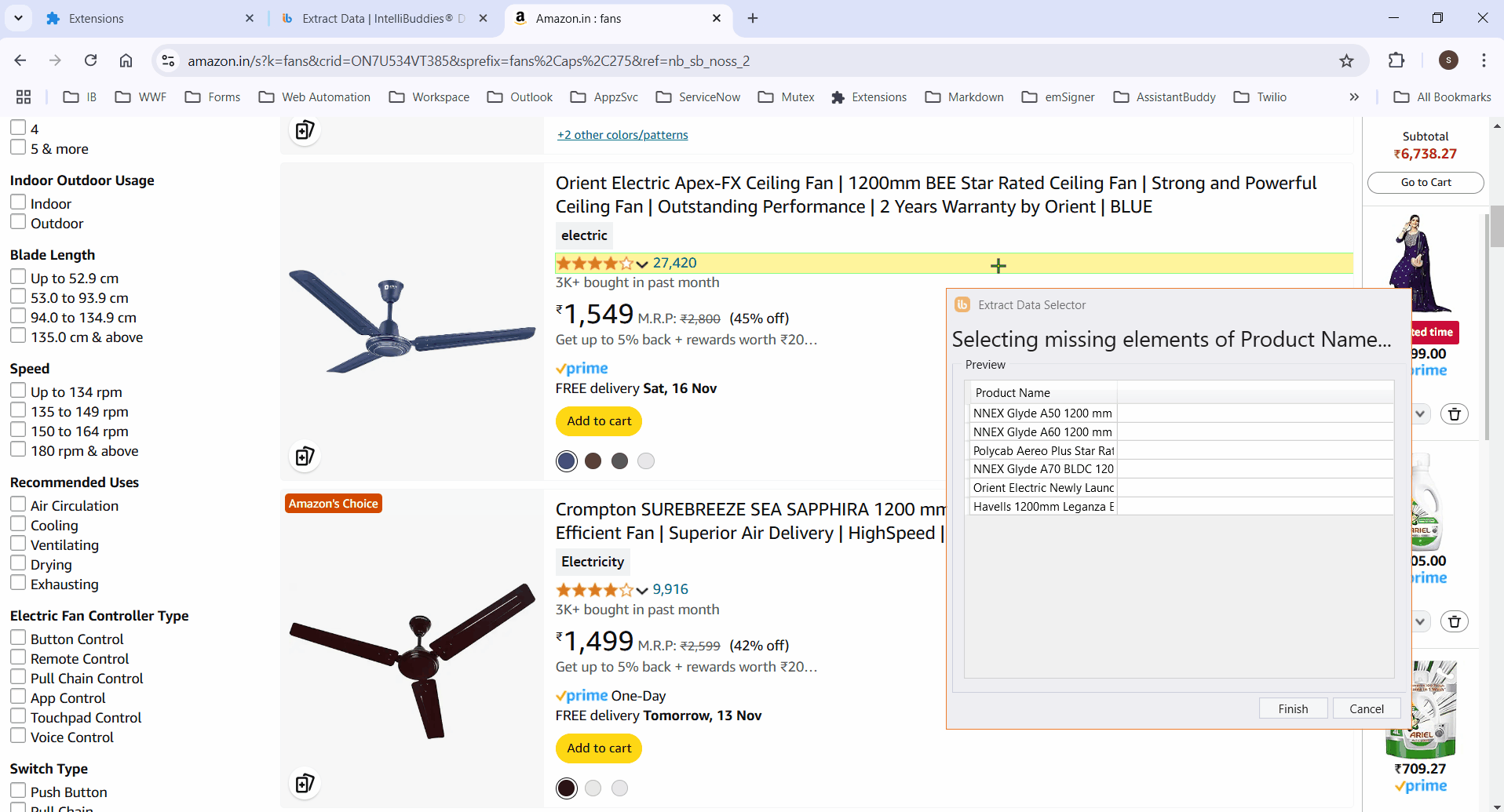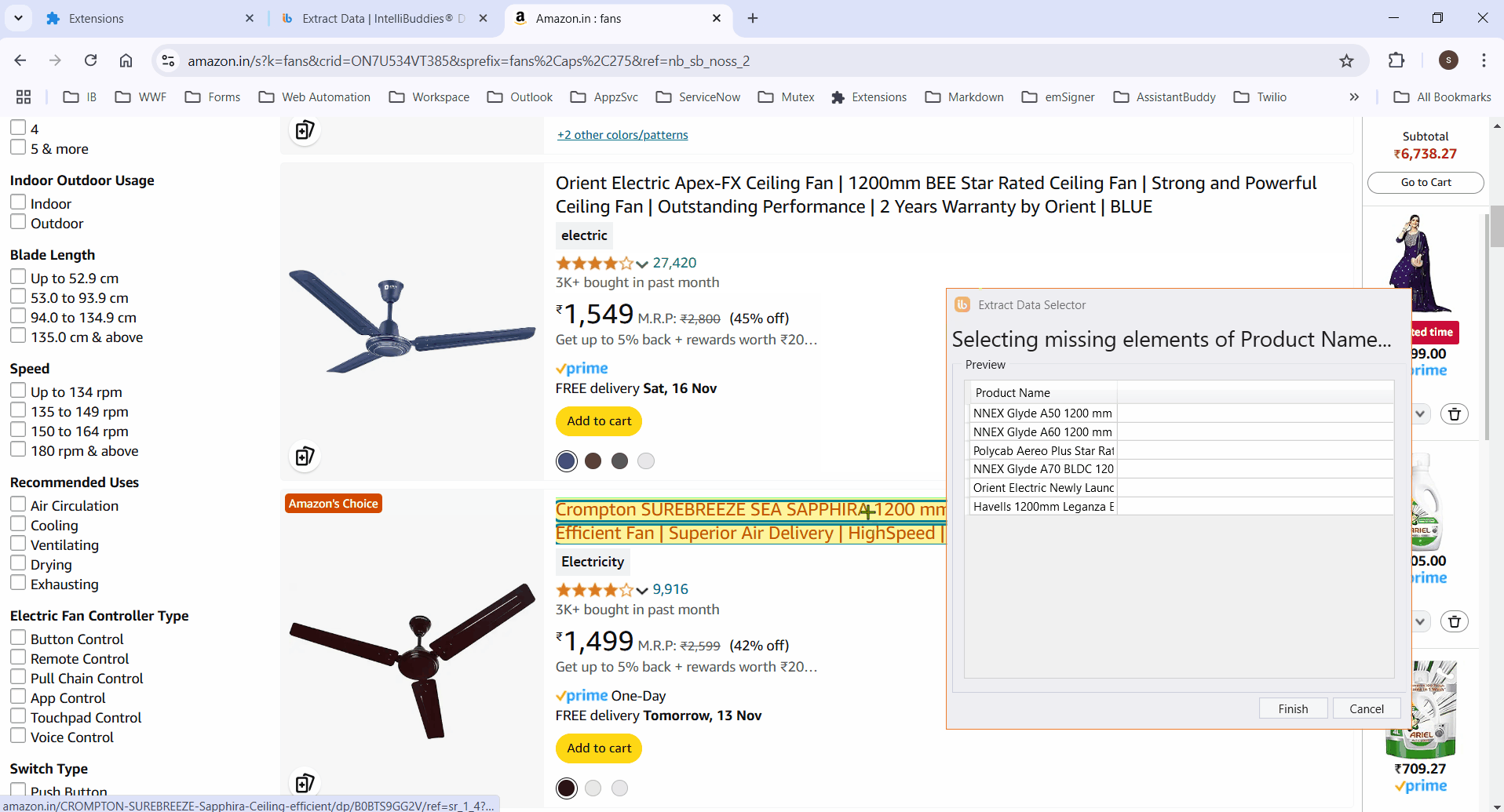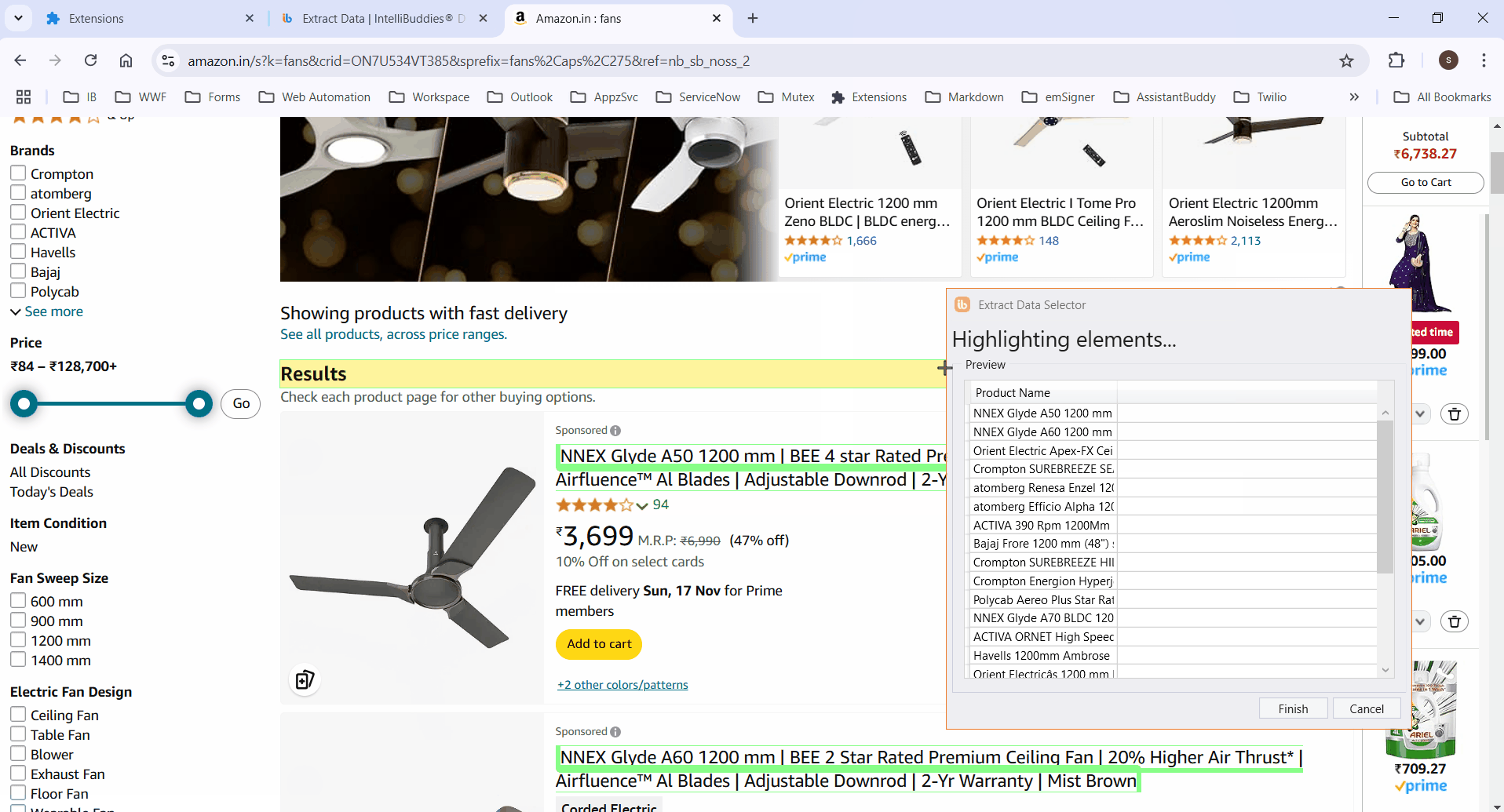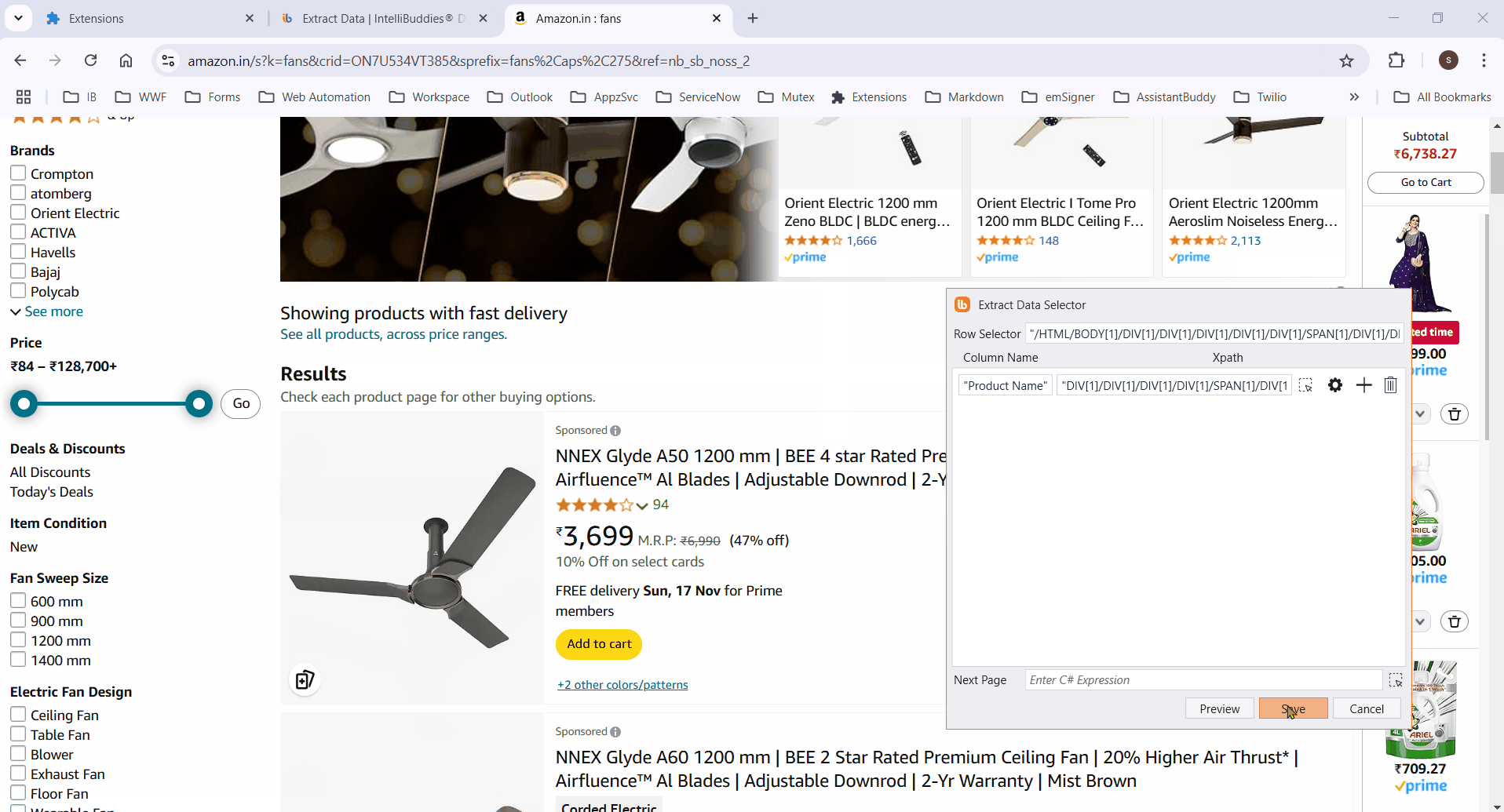
- Select the column element to extract its data. It highlights all matching elements.
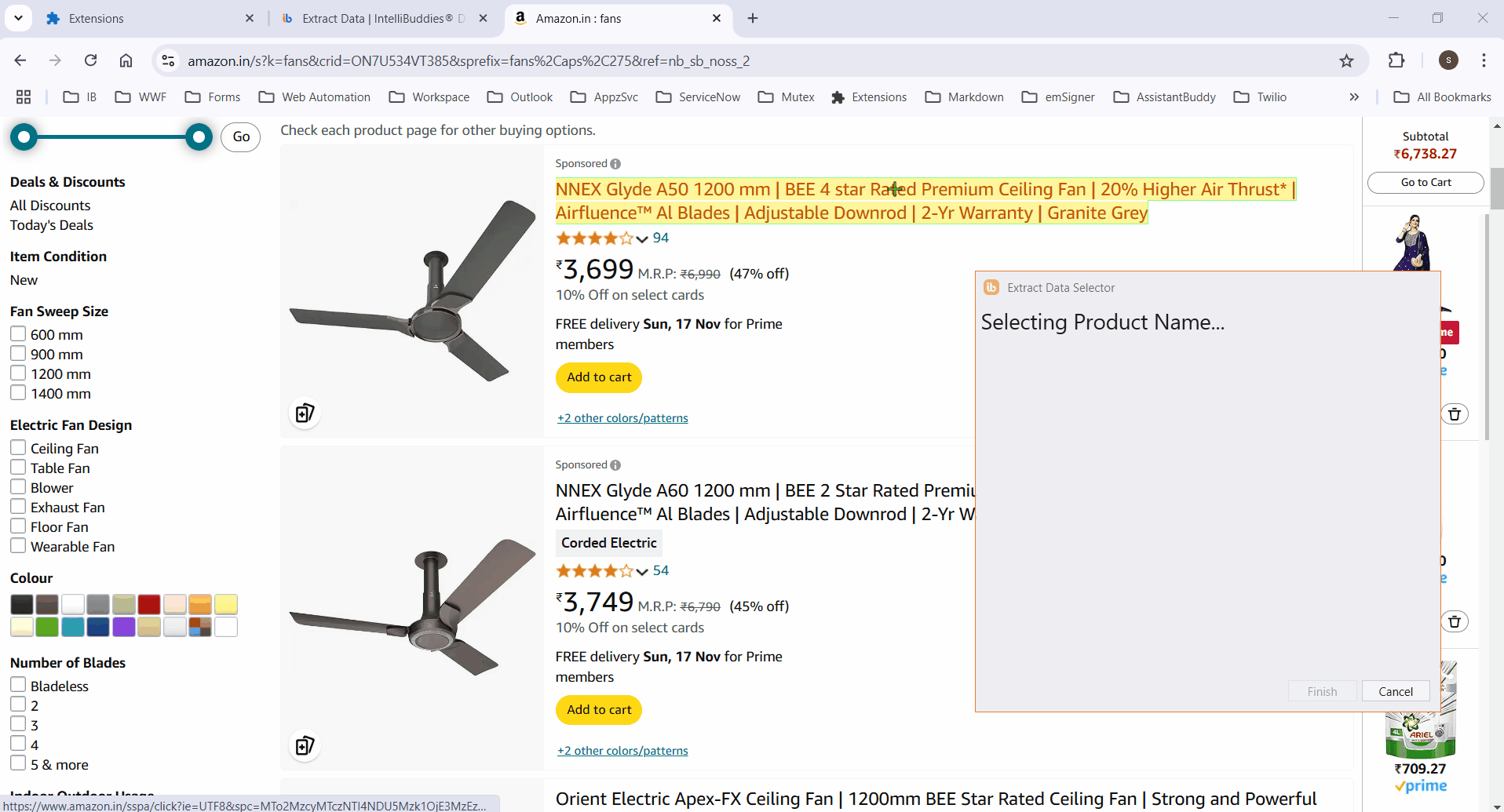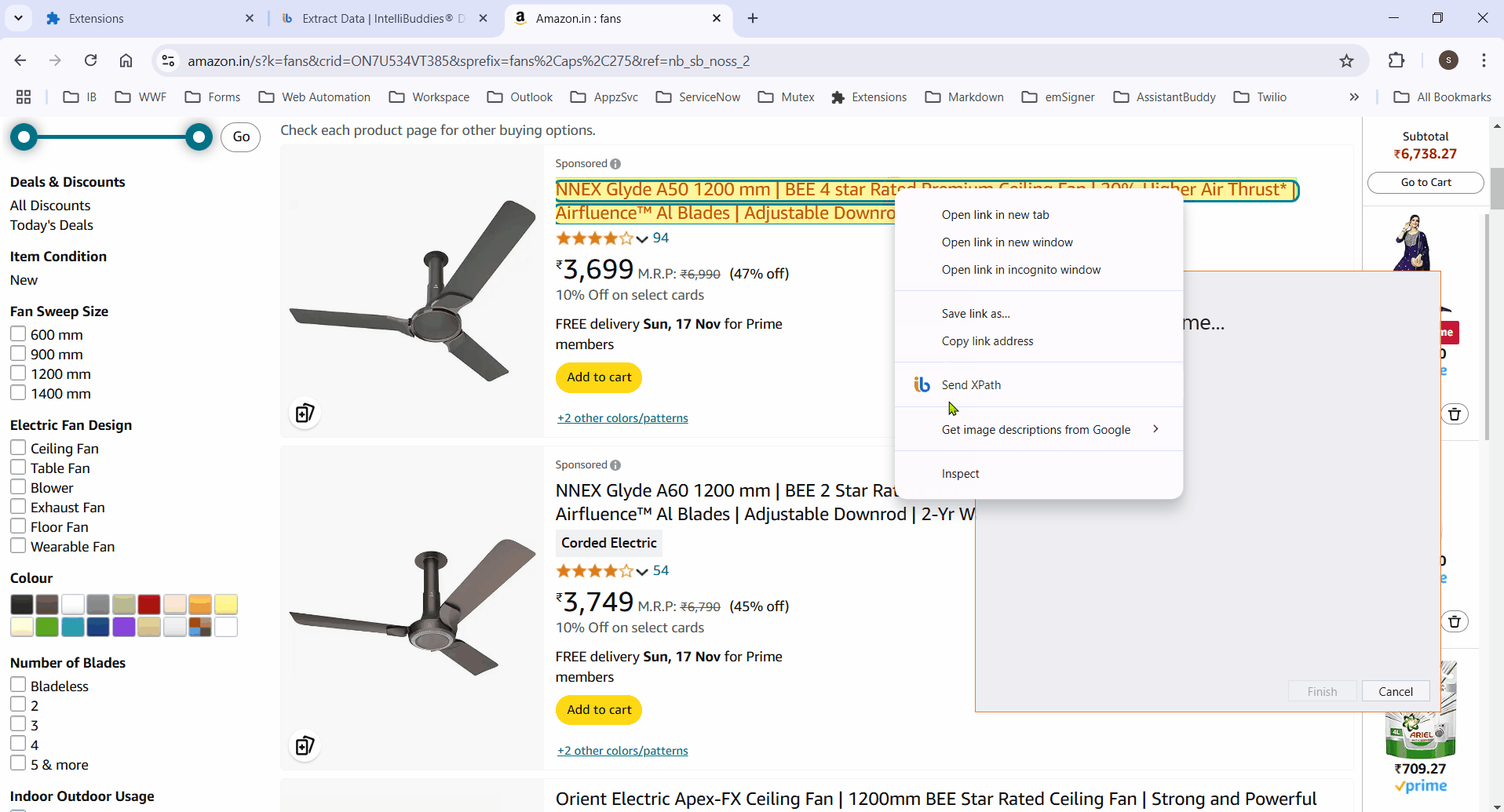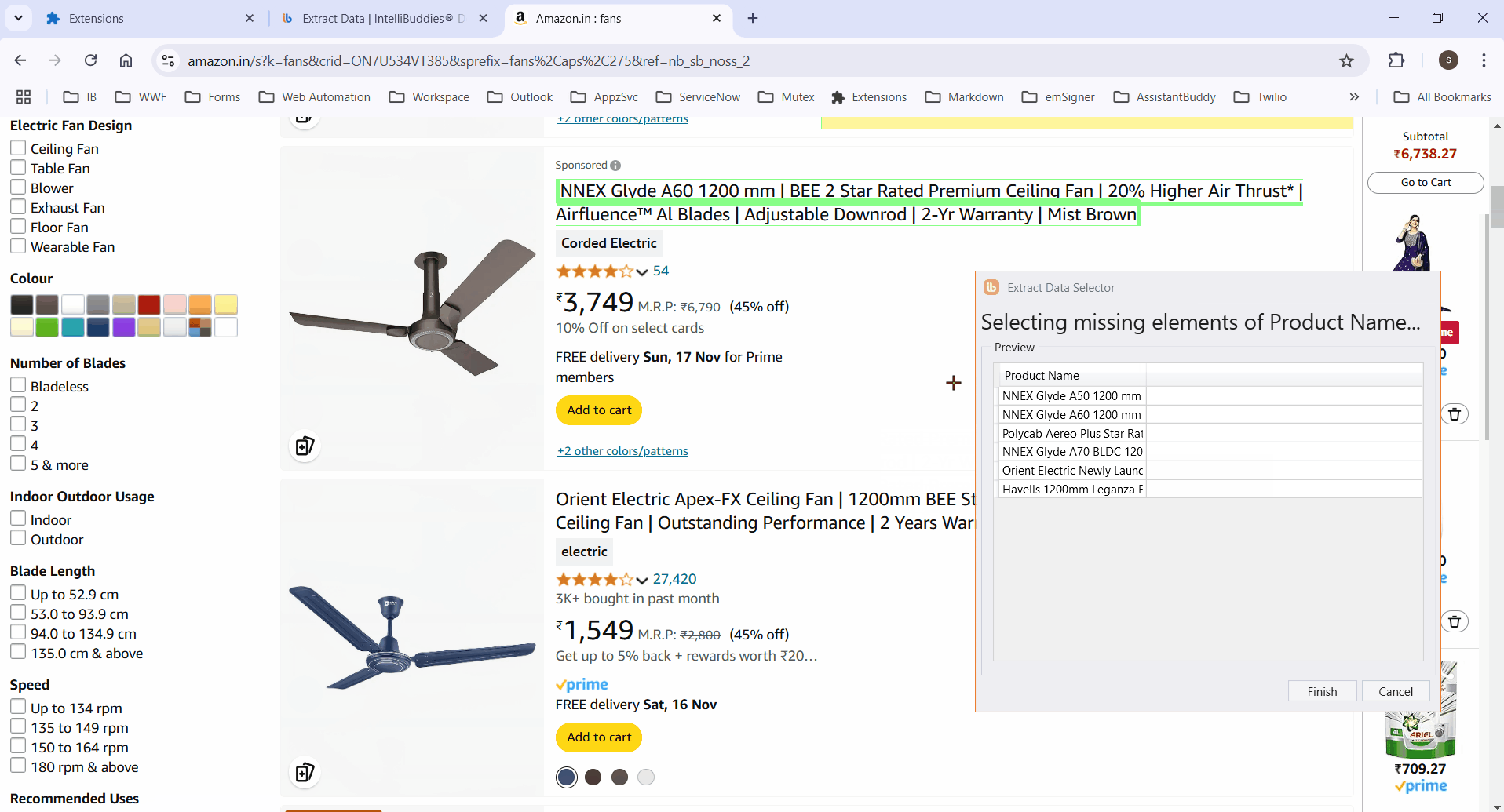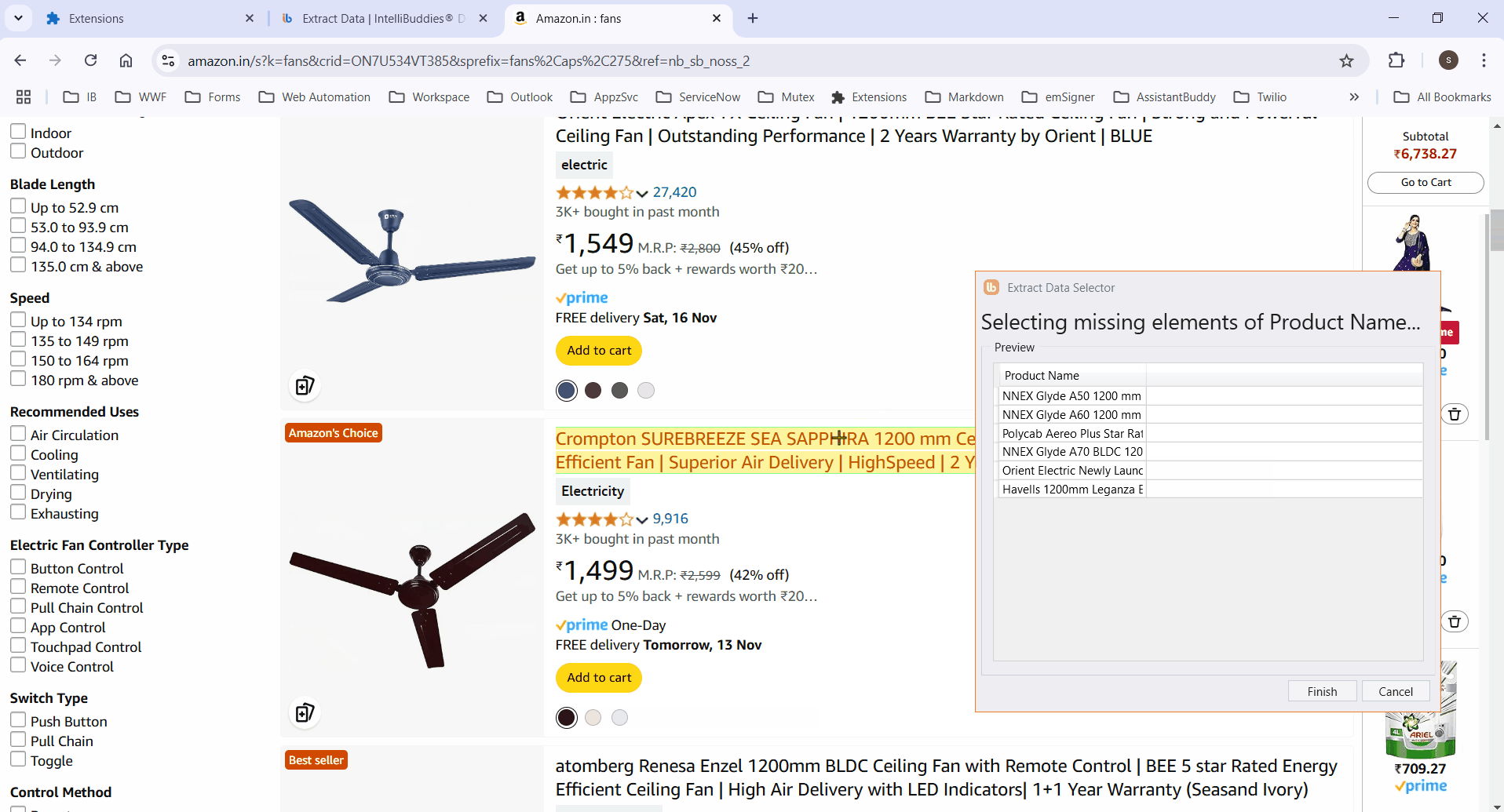
If the process fails to highlight certain elements, manually select them and click Finish to save the selector. The Row Selector and column XPaths will then populate automatically.
- Retrieve specific attribute values from elements by configuring custom attributes.
- Add all required columns by selecting the corresponding elements.

-
To extract data across pages, specify the element to be clicked to move to the next page. Alternatively, click on the
button next to Next Page .
to activate element selection.

-
Click on any column item to highlight all elements in that column.
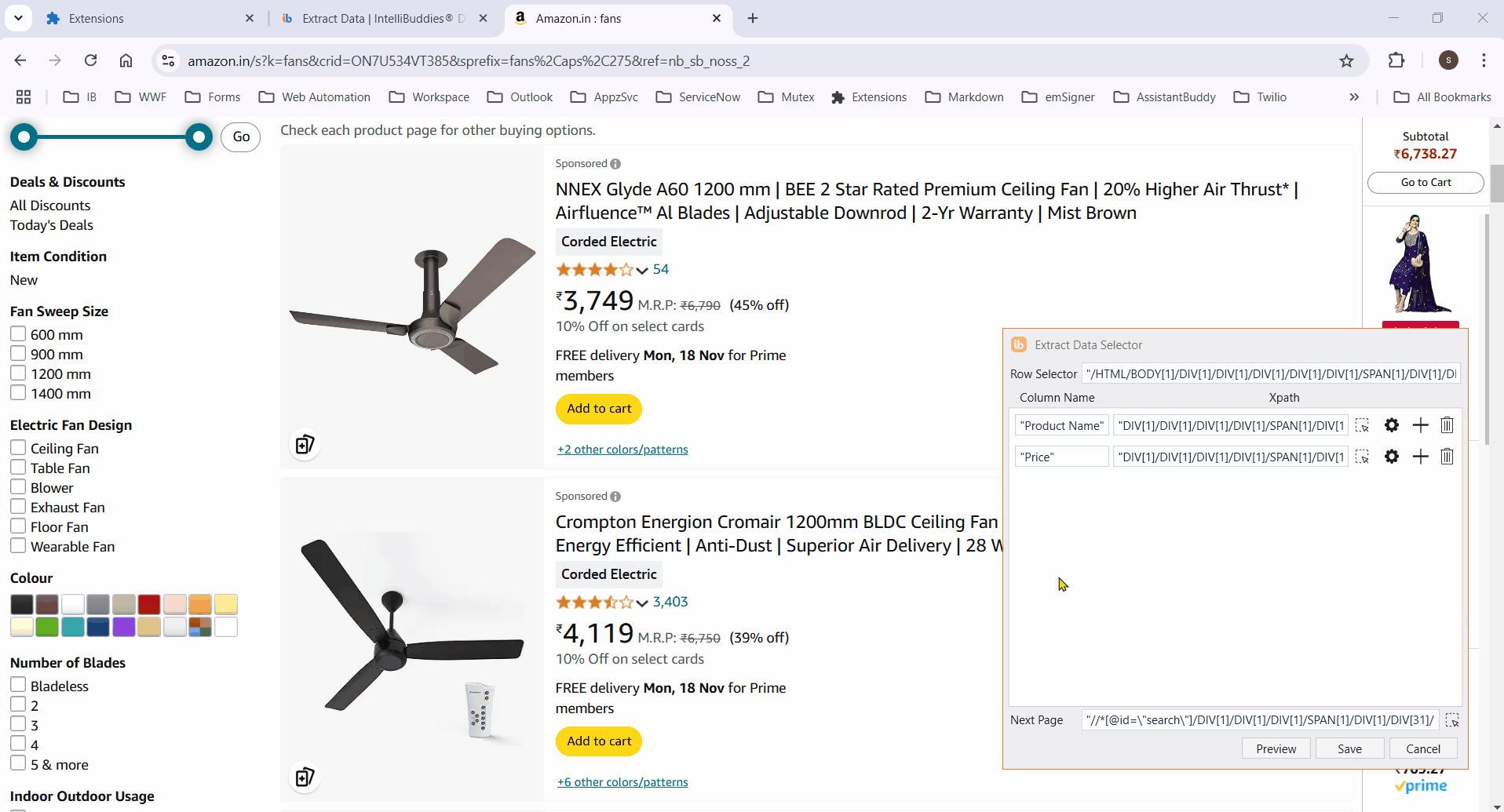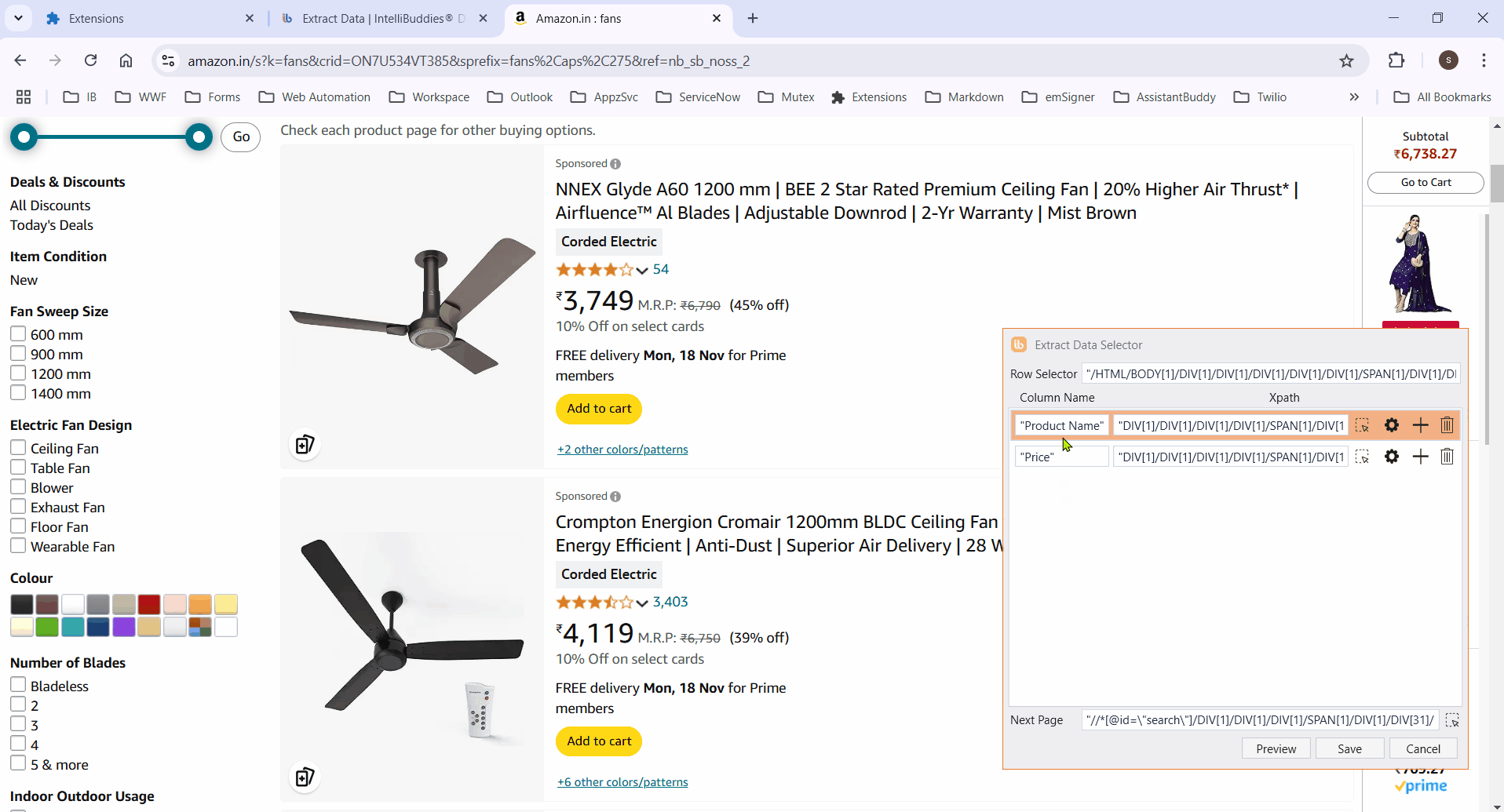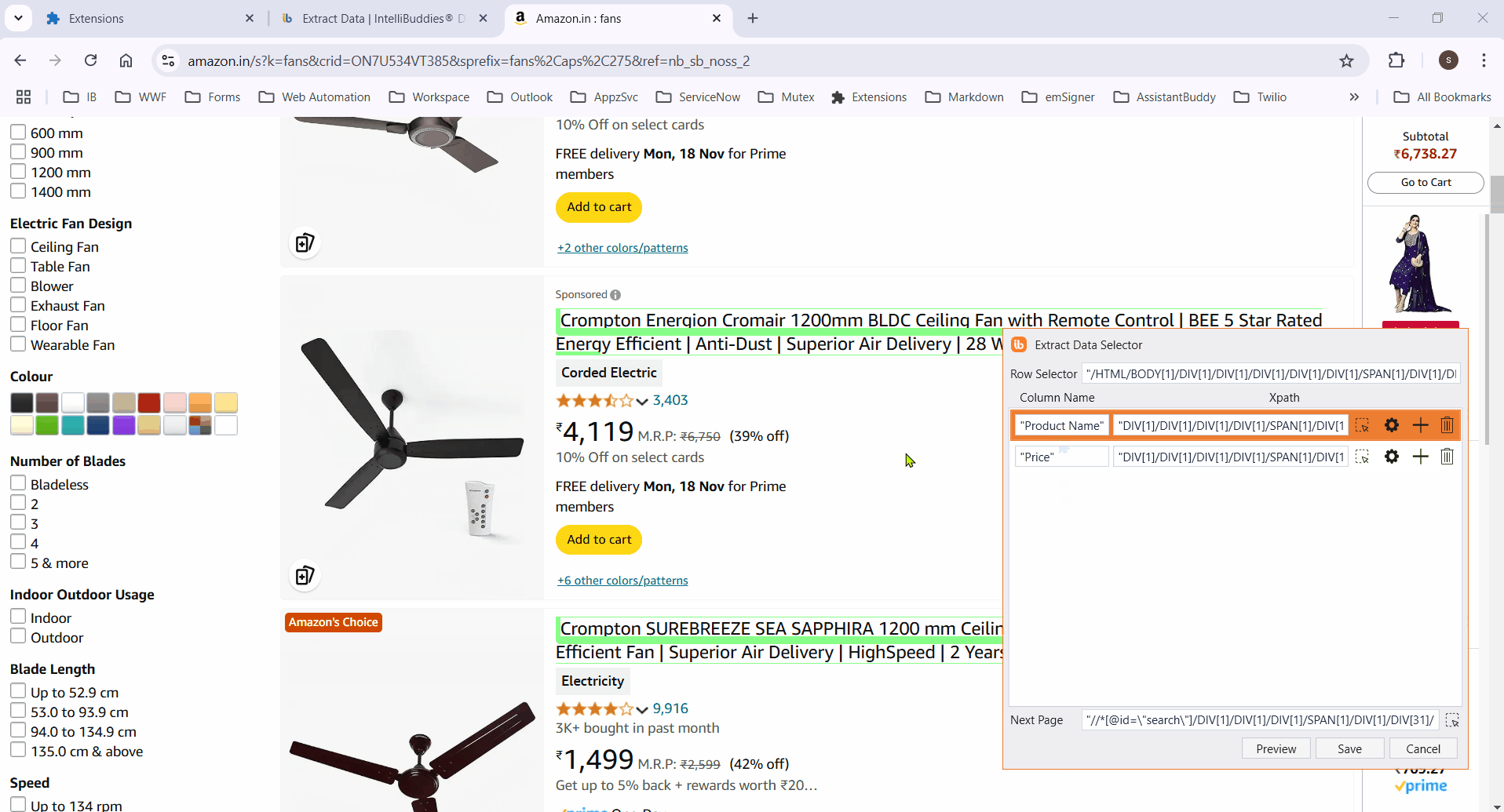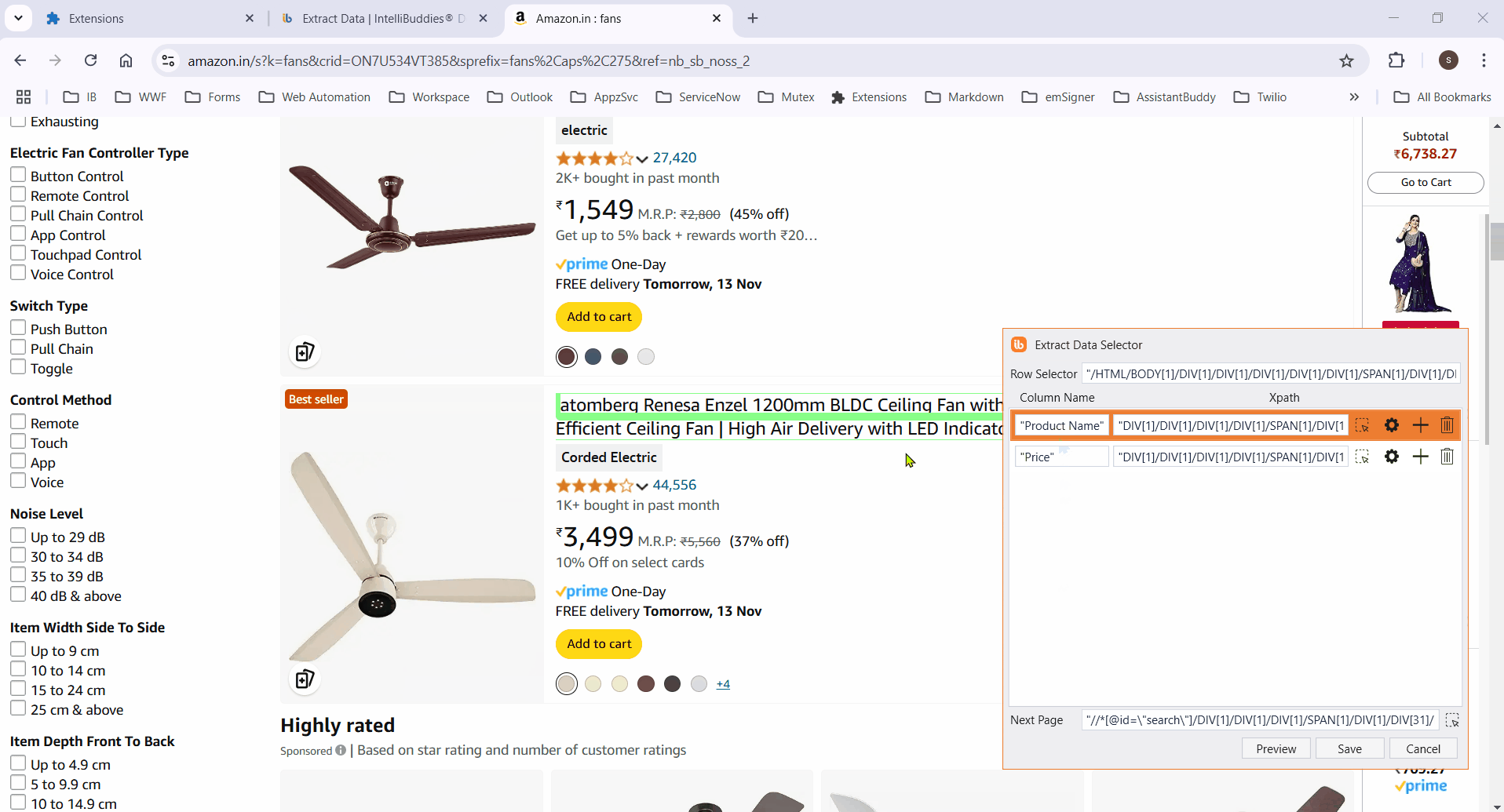
Ensure the selector works across multiple pages. Manually edit XPaths if needed for accuracy.
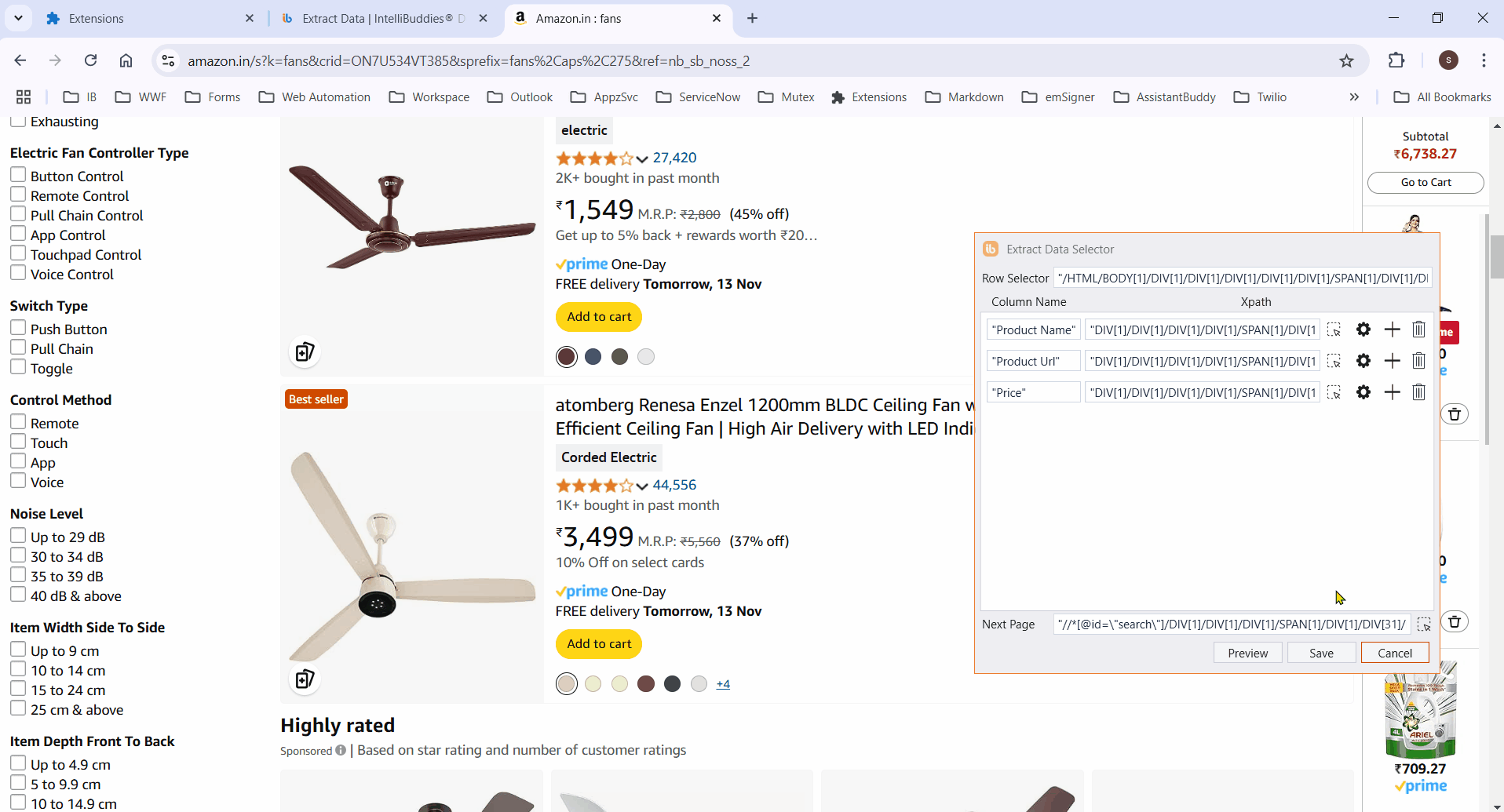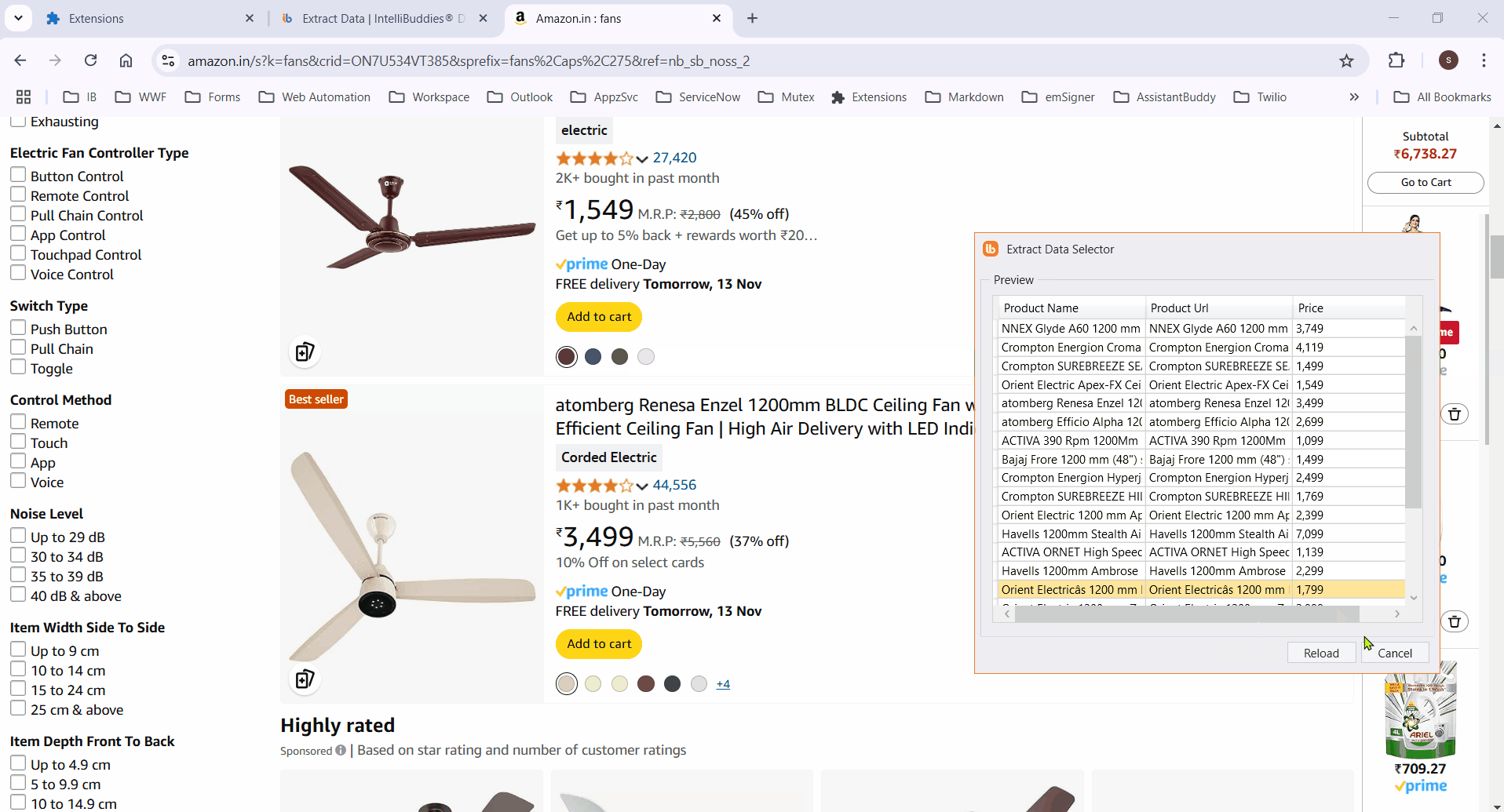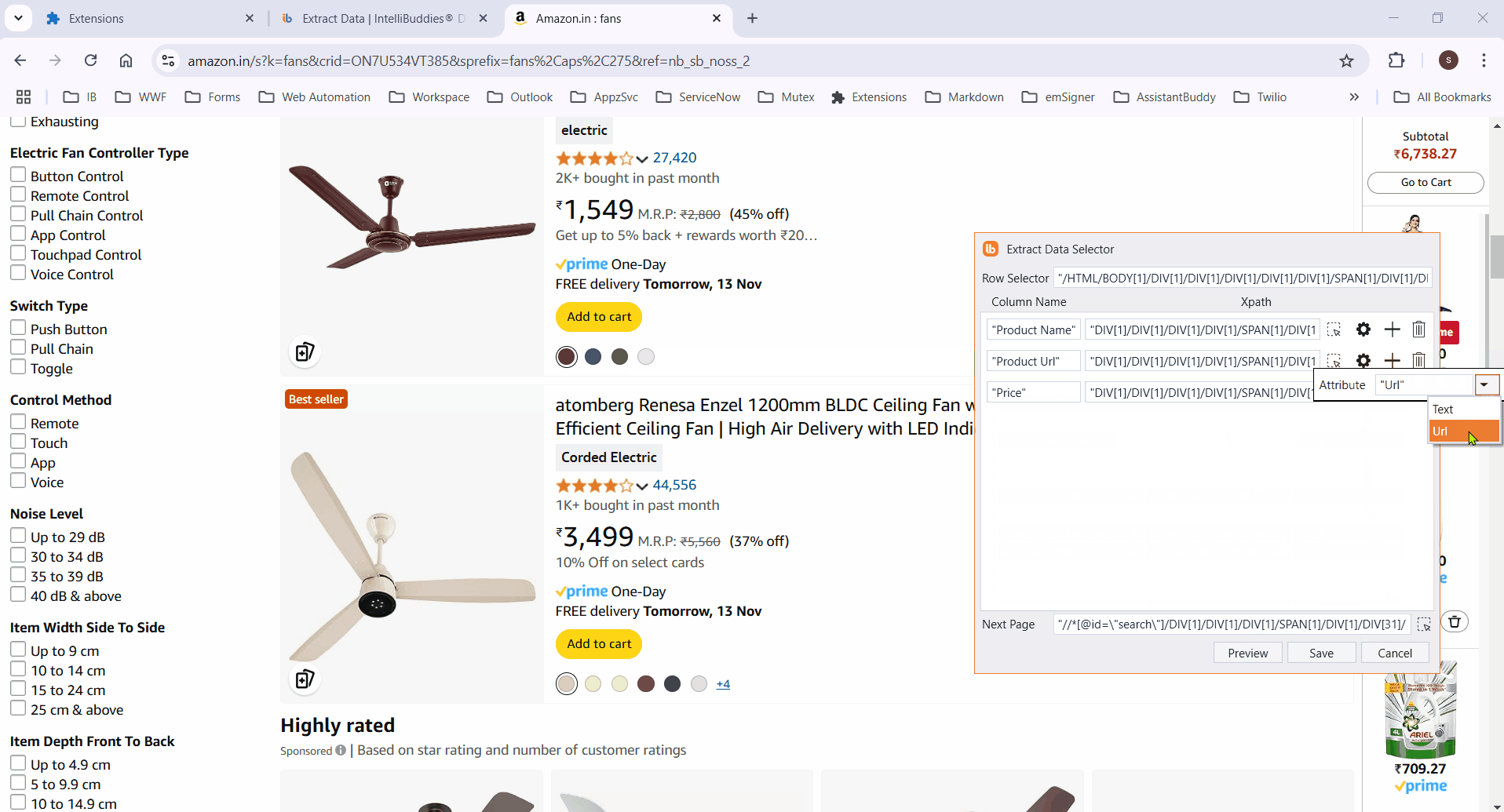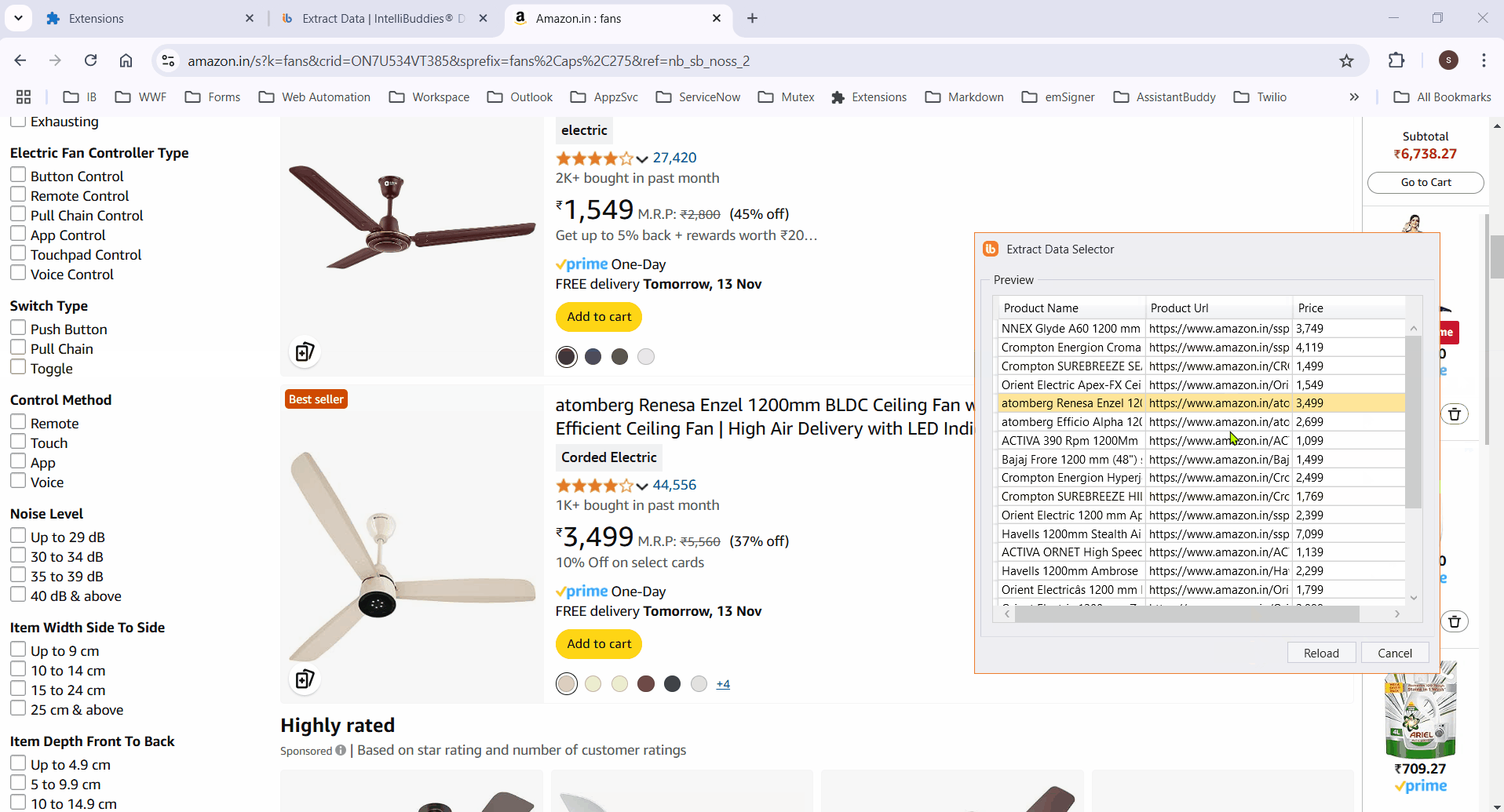
Preview
- Click the Preview button to display the extracted data in a tabular format.
Properties
Input
- Delay (in MS) – Specifies the delay in milliseconds before proceeding to the next page, ensuring adequate page load time.
- Max Records– Defines the maximum number of records from which to extract data. Set -1 to extract all available records.
- Web Page – References the currently opened web page object.
Misc
- DisplayName – Assigns a display name for the activity.
- Private – When enabled, prevents logging of property values within the workflow.
Optional
-
Continue On Error – Defines whether automation continues in case of errors: - True: The workflow proceeds without throwing an exception. - False (Default): The activity throws an exception upon encountering an error.
-
Timeout – Specifies a timeout (Timespan format) for the activity before aborting execution. The default is 10 minutes.
Output
- Result – Stores the extracted data in a structured data table format.
Example
Download Example